After more than 13 years, and tens of thousands of questions, Moz Q&A closed on 12th December 2024. Whilst we’re not completely removing the content - many posts will still be possible to view - we have locked both new posts and new replies. More details here.
Google will index us, but Bing won't. Why?
-
i have the same problem, its not indexing the website.
There is no robot.txt error and I have submitted the sitemap, is there a solution?Link: [https://punknime.com](link url)
-
About two months ago my site dropped off Bing as well. Indexing and ranking fine on Google. But it went from having thousands of pages indexed on Bing to having 0.
I have no errors showing in Bing Webmaster Tools and there are no manual actions as far as I can tell. I submitted a report ticket and didn't hear back after 2 weeks. I submitted another to follow up and haven't heard back for 3 weeks now.
Instead of indexing my site, Bing appears to be indexing multiple IP addresses instead. I haven't changed anything within my DNS records so I'm not sure why this would have suddenly happened.
-
Yesterday I received an email from Bing, stating that they were working on the problem. We will wait to see...
-
Hi, I'm getting the same issue from Bing with my site https://lovefoodfeed.com/. All the pages were listed and indexed until December now every page has been gradually taken off the index over the last month. I opened a support ticket with Bing but no responses yet. My recipe site has no problems on google search console. Bing says there is a malware issue but I use a security plugin and Cloudflare and an A+ rating from site security. Can anyone give any tips?
-
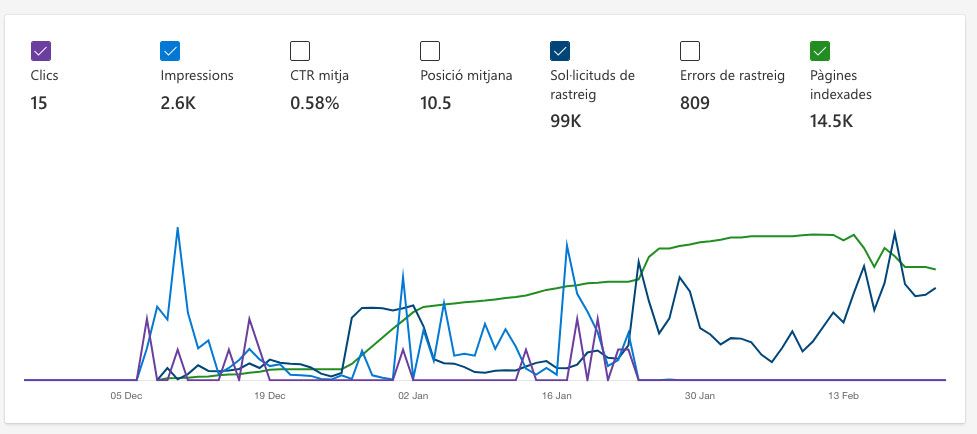
Same issue with [https://bio-farma.es](link url). All is fine at google and yandex, but not in bing. Bing crawler visit the site and say that have 14.5k pages indexed, but in webmaster tools of bing do not appear visits not results. From 24th January 2022 the site dissapears on bing results. I ask at support form of Microsoft, but no answer. No messages at webmaster tools bing. All seems ok, robots.txt, server, etc... In Google all is ok. Tried with indexnow too, with no results. The graph:
-
My site not index in bing. Any one help me
-
I have 5 site in total, 3 of them are already indexed in bing buy the last 2 sites are "Crawled but no indexed"
Don't know what is the issue.
msg to support team but couldn't get any reply.two sites are:
https://www.burnboostofficial.us/burnboosts
https://www.outbackbellyburnerx.us/outback-belly-burner -
@alex_revelinteractive
Same Problem with my website- www.successbeta.com -
Ok
That is an issue with many websites.Recently https://www.healthcaredeliveries.com/ And https://www.sportsmanfinder.com
These 2 sites had bing related issue.
U need to contact support via bing webmaster. Normally they will not tell u exact reason.
When they reply usually in 10 days. Tell them u really need them. And try to ask person that u did some mistakes in past. Like u did email marketing which was getting marked as spam.
And also tell u did fixes in website.
Just say that u accept ur mistakes and promise them that remove your website from manual actions and promise u will not do any spamming.
If u have luck keep answering to the email and doing follow ups.
That’s the way we got our issue sorted.
That can take a process like 2 months
That is my experience and I am indexed in bing.
Thx
-
I am also getting same issue on my site [https://cybetechroom.com] which is indexble on google but not on Bing. i also submit request to Bing webmaster 2 times they tell me same thing i have some issue in my site which is against Bing web master guidelines. i checked whole site lots of time but i don't thing so site have any problem. can any body let me know if someone see anything not good.
-
@alex_revelinteractive yes guy's my site was also not indexing https://tempmail.ac after summiting a forum to bing webmaster support https://www.bing.com/webmaster/support they replied and indexed my site my when i update my new discription and site title and summited back to index the problem is same they are not indexing new updated site since 3-4days.
If you guys having problems what should type in message box of forum i will help you with my message that i used to contact them, if anyone need you can ask here,
Thanks -
I am experiencing the same problem with my site; for some reason Google will index but Bing won't. Have already checked all the usual suspects. Have contacted Microsoft - will keep you guys updated.
-
This post is deleted! -
Same problem with https://nightmareSolution.com
Bing constantly crawl the website but for some unknown reason, bing won't index the website.However, everything is fine on the side of Google and Yandex, it takes Less than 24 hours for Google to index a new blog post.
I think the problem is with Bing and not the website?
Anyone here found a solution? -
Has anyone solved this problem? My website is not indexed by Bing either. Everything had been checked. Website: https://www.walkingpad.com/
-
@bcammo Hey, may I ask you how did you solve your issue and what exactly was wrong?
I got:
Indexed but cannot be served. URL cannot appear on Bing
Last crawl attempted: 04 Aug 2021 at 18:49
Crawl allowed? Yes.
Page Fetch: Successful.
Indexing allowed? Yes.
Index
Canonical URL - -
The inspected URL has been indexed successfully but there are some issues which might prevent us from serving it to our users. Please contact Bing Webmaster support for more detailsI ask support but got 2 generic replies so far telling me that I need to review their guidelines and fix the issues but I don’t know what those issues are. All I see is 2 dash lines in the last line at “Canonical URL” and I don’t know what that means? I am very frustrated because I got no issues at all in Google and MS won’t tell me what is wrong.
-
Hi
I have same problem. Website is 2 to 3 years old.
Our website is indexed very well on Google and have listing on 1st page of google for many keywords.
However site is not getting indexed on Bing.
We emailed them few times and just a normal reply saying, follow guidelines.
But we have no clue what we need to do.
Error:
Blocked
URL cannot appear on BingWeb site url is: https://www.bulkcheapammo.com
Any one got it fixed? @Moz Any suggestions please?
-
Yes, sorry
")
I used the form on their support site for the webmaster tools : https://www.bing.com/webmaster/support
Although that doesn't seem to be working at this moment so the email address that it was sent to is :
Hope this helps!
-
Just encase anyone is still having issues with this, or happens to come across this post in the future...
We emailed Bing support who came back and said that they had found their bots were blocked from indexing our site, there was no reason for this but just an error in their system (apparently this is quite common).
They responded pretty quickly and removed the block, a couple of days later we were being indexed and seeing traffic come from Bing!
-
We are having the same issue with one of our sites. We have tried all of the suggestions we can find on the internet.
Submitted out site to Bing webmaster tools, submitted the Sitemap, checked the Robots.txt...
It is now crawling the site but still not indexing any of the pages! The only thing left for us to do is wait and hope that Bing will eventually index it, but it seems weird as its being indexed fine in other search engines and generally getting good search engine rankings for keywords.
The website is www.thriveinlife360.com for reference.
We have a client base of well over 20 websites and all of them are being indexed in Bing, except from this one.
Would be interesting to know how many websites this affects and if there is a pattern within those that Bing doesn't like.
-
 This is highly confounding. I've crawled as Bingbot and nothing is in it's way.
This is highly confounding. I've crawled as Bingbot and nothing is in it's way.There are a few other issues though. You are using the canonical on a large number of pages. In my crawl, I am seeing the crawler going through a large number of pages and only returning a fraction of them. At this moment my crawler is finding 31k things to crawl, has crawled 1044 and returned only 29 pages that might be indexed. 65% of those are without errors.
It is possible that the site structure is causing issues. I suggest taking time to review your site structure and making it easier for bots to find the pages they need to index, telling them what not to crawl (a canonical is a suggestion and should be used when pages are duplicated), and fixing all errors on the site.
-
Thanks, Kate! Unfortunately, we've tried all those idea already too.
- We've contacted ads, but on luck in connection there.
- We've submitted to webmaster tools; the site is getting crawled but not indexed.
- We’ve submitted the sitemap manually, as well.
-
Not seeing anything overtly wrong. I submitted your homepage to Bing for indexing, so we'll see what happens there.
2 other things though.
- You advertise. Get a hold of the ads side and see if they know anything or if they can connect you with anyone. It's a long shot, but worth a try.
- Have you verified your site in Bing Webmaster Tools and submitted your sitemap manually?
-
Yes! The domain is http://www.pamandgela.com/
Thank you!
-
Can you provide your domain please?
-
How to use Fetch as Bingbot
Fetch as Bingbot is a very useful tool for troubleshooting. You will find this tool in the Diagnostics & Tools section in the navigation menu. **Fetch as Bingbot **allows you to see exactly what the Bingbot sees when downloading a page from your site. As such, it’s a great tool for determining if a page on your site can be crawled. To use it, simply enter in the URL from your site and click Fetch. This tool will send the request to Bingbot for processing, so it’s normal that it takes a few seconds to run your request. Just below the URL entry form, the URL you requested (along with any previous requests) will be shown. When Bingbot is finished with your request, the status for the URL will change to Completed. To see what Bingbot found at your URL, simply click the **Completed **link and scroll down the page to view the page source that Bingbot found.
SEE WHAT BINGBOT SEES
Fetch as Bingbot shows you exactly what your HTTP Headers and page source look like to Bingbot. Viewing your page’s source in this manner ensures you know exactly what Bingbot is seeing when it crawls the URL. This is especially useful in helping find areas when you want to make sure content can be indexed or in cases where your site may have been compromised and is for example sending different HTML to Bingbot then to users. By scanning through the page source, you could note things like links injected into blog posts or any other manner of additive items you did not place on your website.
Fetch as Bingbot is also a reliable way to test if a URL is being blocked by your robots.txt file. It’s polite, so sending it to fetch a URL blocked via robots.txt will get you a notice explaining that this barrier is in place.
Also, if Fetch as Bingbot is not able to crawl a page because of other blocks or politeness constraints, for example the maximum amount of crawls we are allowed to make in a given time window, the tool will tell you too.
|
NOTE |
| To see the crawled content of a page using the crawlable Ajax protocol using #! notation in the URL, you need to input the static URL instead. The static URL is the URL that contains the ?escaped_fragment= portion. Note that although Bing supports this protocol we do not recommend it for frequent use. |COMMON PROBLEMS
WHAT DOES "REDIRECTION LIMIT REACHED MEAN"?
Unlike the SEO Analyzer tool, Fetch as Bingbot does not follow redirects. Instead it will let you know that the page resulted in a redirect and shows you the HTTP headers it received from your server. The line most commonly starting with HTTP/1.1 shows the status code (301, 302, or in some cases 303 or 307 - see this full list of 3xx status codes) and the location: header shows you where the server tells Bingbot (and other clients) where the redirect should go to. To fetch the page at that location you will need to perform a new fetch using that URL. This is in fact how the Bingbot crawler works: every redirect requires a brand new fetch, and this new fetch does not necessarily happen immediately after encountering the redirect.
WHAT DOES "DOWNLOAD OF ROBOTS.TXT FAILED" MEAN?
When the result of a fetch reads “Download of Robots.txt Failed”, then Bingbot was not able get a proper server response when trying to access your site’s robots.txt. This usually means that your site’s server is configured to refuse Bingbot or the IP addresses from which Bingbot operates a proper connection or simply denies access to this URL. This is a problem, since Bingbot now cannot tell whether or not a robots.txt file actually exists nor read any directives in the robots.txt file should it exist. You should investigate (or ask your ISP to investigate) whether such a configuration is in place.
WHAT DOES "REPRESENT DOWNLOAD NOT ATTEMPTED DUE TO POLITENESS ISSUE" MEAN?
When the result of a fetch reads “Represent download not attempted due to politeness issue”, then Bingbot did not try fetch the page due to restrictions on how much we can crawl the site. This usually means that Bingbot is backing off at this point in time and that it cannot fetch the page "politely", that is, honoring crawl delays or heuristically determined maximum fetches per second for your site. If this issue persists it may point to insufficient bandwidth available to Bingbot to crawl your site efficiently. First, you should check your site's robots.txt for any crawl-delay: directives. Removing or lowering crawl-delay directives can also help with this issue. If there are no crawl-delay directives present, you should check Crawl Control settings to see if they can help improve by setting higher levels (especially during times when you expect fewer visitors).
WHAT DOES "UNEXPECTED ERROR" MEAN?
If you are seeing frequent "Unexpected Error" results in Fetch as Bingbot, this may indicate that our crawler is not able to connect to your server and not getting a server response at all. Your server may be unintentionally blocking Bingbot based on user agent or IP range. To remedy this, look for server configurations or modules that may be dropping connections for Bingbot or work with your ISP to identify whether the issue is on their side.
You can find more information on troubleshooting issues at Bing Webmaster Tools Help & How-To Center
Got a burning SEO question?
Subscribe to Moz Pro to gain full access to Q&A, answer questions, and ask your own.
Explore more categories
-
Chat with the community about the Moz tools.
-
Discuss the SEO process with fellow marketers
-
Discuss industry events, jobs, and news!
-
Chat about tactics outside of SEO
-
Dive into research and trends in the search industry.
-
Support
Connect on product support and feature requests.
-