After more than 13 years, and tens of thousands of questions, Moz Q&A closed on 12th December 2024. Whilst we’re not completely removing the content - many posts will still be possible to view - we have locked both new posts and new replies. More details here.
Unsolved error in crawling
-
hello moz . my site is papion shopping but when i start to add it an error appears that it cant gather any data in moz!! what can i do>???
-
I am seeing errors ehsaas8171.com.pk and find solutions
-
@AmazonService Thanks! You can check crawling of this Website
-
@husnainofficial Got it! Noted, I'll make use of the Indexing API for faster crawling and indexing, especially when dealing with persistent crawling errors related to 'Amazon advertising agency'. Appreciate the guidance!
-
It could be q is looking at different metrics, here on Moz, the DA of mine MAQUETE ELETRÔNICA is higher than q on the other sites
-
If Crawling Error Persist, use Indexing API for Fast Crawling and Indexing
-
I'm also looking for a solution. because I also facing the same problem for the last 1 month on my website.
-
check this my site i have audit on moz there are lots of error crawling the pages why visit: https://myvalentineday.com
-
@valigholami1386 https://yugomedia.co/ click this?
-
ghfghdgvgkjbn b
-
If you're using Google Search Console or a similar tool, look into the crawl rate and crawl stats. This information can provide insights into how often search engines are accessing your site.
-
Hello Moz,
I have a site, [https://8171ehsaasprogramme.pk], but I'm encountering an error while trying to add it to Moz. It says it can't gather any data. What can I do to resolve this issue?
-
@JorahKhan Hey there!
 It sounds like you're dealing with some crawling and redirection issues on your website. One possible solution could be to check your site's robots.txt file to ensure it's configured correctly for crawling. Additionally, inspect your server-side redirects and make sure they're set up properly. If the issue persists, consider reaching out to your hosting provider for further assistance. By the way, I faced a similar problem on my website https://rapysports.com/, but it's now running smoothly after implementing this strategy. So, give it a shot! Good luck, and I hope your website runs smoothly soon!
It sounds like you're dealing with some crawling and redirection issues on your website. One possible solution could be to check your site's robots.txt file to ensure it's configured correctly for crawling. Additionally, inspect your server-side redirects and make sure they're set up properly. If the issue persists, consider reaching out to your hosting provider for further assistance. By the way, I faced a similar problem on my website https://rapysports.com/, but it's now running smoothly after implementing this strategy. So, give it a shot! Good luck, and I hope your website runs smoothly soon! 

-
@JorahKhan said in error in crawling:
I am having crawling and redirection issues on this https://thebgmiapk.com , Suggest me a proper solution.
Hey there!
It sounds like you're dealing with some crawling and redirection issues on your website. One possible solution could be to check your site's robots.txt file to ensure it's configured correctly for crawling. Additionally, inspect your server-side redirects and make sure they're set up properly. If the issue persists, consider reaching out to your hosting provider for further assistance. By the way, I faced a similar problem on my website, but it's now running smoothly after implementing this strategy. So, give it a shot! Good luck, and I hope your website runs smoothly soon! -
To fix website crawling errors, review robots.txt, sitemaps, and server settings. Ensure proper URL structure, minimize redirects, and use canonical tags for duplicate content. Validate HTML, improve page load speed, and maintain a clean backlink profile.
-
To fix website crawling errors, review robots.txt, sitemaps, and server settings. Ensure proper URL structure, minimize redirects, and use canonical tags for duplicate content. Validate HTML, improve page load speed, and maintain a clean backlink profile.
-
cool really cool
-
There are a few general things you can try to troubleshoot the issue. First, ensure that you have entered the correct URL for your website. Double-check for any typos or errors in the URL.
Next, try clearing your browser cache and cookies and then attempting to add your website again. This can sometimes solve issues related to website data not being gathered properly.
If these steps don't work, you can contact Moz's customer support for further assistance. They have a dedicated support team that can help you with any technical issues related to their platform.
I hope this helps! Let me know if you have any further questions or if there is anything else I can assist you with.
Best Regards
CEO
bgmi apk -
If we are experiencing crawling errors on your website, it is important to address them promptly as they can negatively impact our search engine rankings and the overall user experience of our website.
Here are some steps we can take to address crawling errors:
Identify the specific error: Use a tool like Google Search Console or Bing Webmaster Tools to identify the specific errors that are occurring. These tools will provide detailed information about the errors, such as the affected pages and the type of error.
Fix the error: Once we have identified the error, take the necessary steps to fix it. For example, if the error is a 404 page not found error, we may need to update the URL or redirect the page to a new location. If the error is related to server connectivity or DNS issues, we may need to work with our hosting provider to resolve the issue.
Monitor for additional errors: After fixing the initial error, continue to monitor our website for additional errors. Use the crawling tools to identify any new errors that may arise and address them promptly.
Submit a sitemap: Submitting a sitemap to search engines can help ensure that all of our website's pages are indexed and crawled properly. Make sure that our sitemap is up-to-date and includes all of our website's pages.
By following these steps, we can help ensure that our website is properly crawled and indexed by search engines, which can improve our search engine rankings and the overall user experience of our website.
I have fixed the same problem with my built image editing service providing the company's website
-
I am having crawling and redirection issues on this https://thebgmiapk.com , Suggest me a proper solution.
-
Noida Hotels Escorts
Call Girls in Sarfabad Call Girls in Harola Call Girls in Noida Ghaziabad Escorts Greater Noida Escort Gaur City Escorts Noida Hotel Escorts Vijay Nagar Escorts Noida Online Dating Escorts Noida Call Girls Noida Call Girl Laxmi Nagar Escorts Delhi Escorts Dadri Escorts Ashok Nagar Escortshttps://noida-escort.live/independent_connaught_place_escorts/
https://noida-escort.live/chhatarpur_escorts_call_girls_services/
https://noida-escort.live/chanakyapuri_escorts_services_24_7_open/
https://noida-escort.live/aerocity_escorts_girls_vip_services/
https://noida-escort.live/delhi_call_girls_vip_escorts_services/ -
Hello
Yes there is a new update in google search console that's why many website facing this issue.
-
<a href="https://noidagirlsclub.blogspot.com/2021/12/call-girls-noida-sector-55.html">Noida call girls photo</a>
<a href="https://www.noida-escort.com/2021/12/gamma-2-greater-noida-escorts.html">escort in gamma 2, Greater noida</a>
<a href="https://www.noida-escort.com/2021/12/gamma-2-greater-noida-escorts.html">Greater noida escort in gamma 2</a>
<a href="https://www.noida-escort.com/2020/10/greater-noida-escorts.html">call girl in Greater Noida</a>
<a href="https://www.noida-escort.com">escort in Noida</a>
<a href="https://www.noida-escort.com">Noida escorts service</a>
<a href="https://www.noida-escort.com">Noida escorts</a>
<a href="https://www.noida-escort.com/2021/12/gtb-nagar-call-girls.html">GTB nagar call girls</a><a href="https://noidaescort.club/">Noida Escorts</a>
<a href="https://noidacallgirls.in">Noida Call Girl</a>
<a href="https://simrankaur.in">Escort in Noida</a>
<a href="https://www.callgins.com">Noida Call Gins</a>
<a href="https://noidacallgirls.in">Noida Call Girls</a><a href="https://www.noida-escort.com/2020/03/college-call-girl-escorts-noida.html">noida collage call girls </a>
<a href="https://www.noida-escort.com/2019/06/noida-body-to-body-topless-massage.html">sex massage noida</a>
<a href="https://www.noida-escort.com/2019/06/noida-body-to-body-topless-massage.html">sex massage in noida</a>
<a href="https://www.noida-escort.com/2020/06/call-girls-gamma-noida.html">cheap escorts in noida</a>
<a href="https://www.noida-escort.com/2020/10/greater-noida-escorts.html">call girls in greater noida</a>
<a href="https://www.noida-escort.com">female escort in noida</a>
<a href="https://www.noida-escort.com">female escort service in noida</a>
<a href="https://www.noida-escort.com/2020/05/door-to-door-escorts-services-in-noida.html">hookers in noida</a>
<a href="https://www.noida-escort.com/">noida escorts service</a>
<a href="https://www.noida-escort.com/">noida escorts</a><a href="https://www.noida-escort.com/">noida escort</a>
<a href="https://www.noida-escort.com/2020/05/door-to-door-escorts-services-in-noida.html">call girl in noida</a>
<a href="https://www.noida-escort.com/2020/03/call-girls-in-hoshiyarpur-sector-51-noida.html">cheap call girls in noida</a>
<a href="https://www.noida-escort.com/2020/03/call-girls-in-hoshiyarpur-sector-51-noida.html">cheap call girls noida</a>
<a href="https://www.noida-escort.com/2020/03/call-girls-in-hoshiyarpur-sector-51-noida.html">cheap call girls greater noida</a> -
techgdi providing best seo audit services
https://www.techgdi.com/best-seo-company-in-london-uk/
#seoaudit #crawl -
better to check in webmaster tool,
#crawl #check -
For that will do one thing you just use the best crawling software and get the best result. I hope after using this method the problem will be solved.
-
@nutanarora
Same problem with my website
html table generator -htmltable.org -
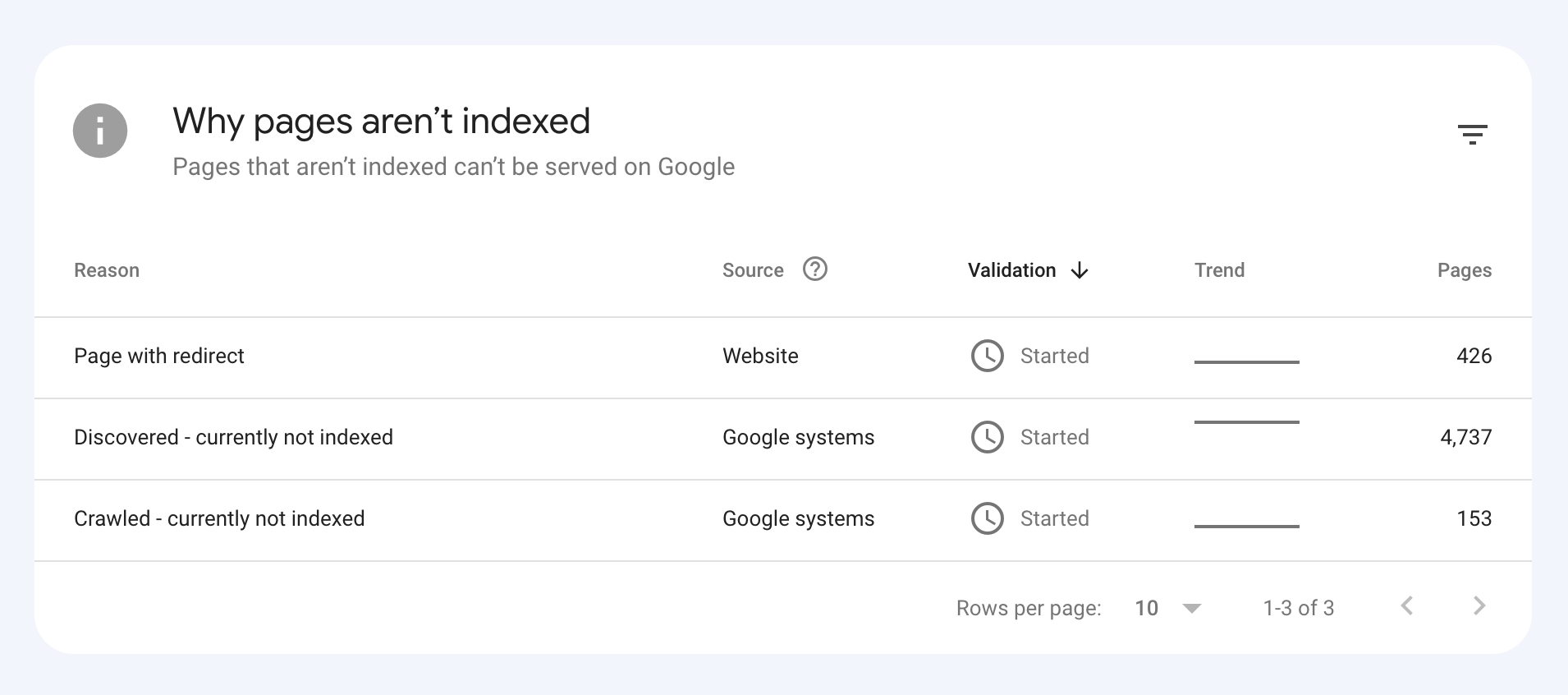
There are lots of urls are showing in Google webmaster tools whose are giving error in crawling. My website url is https://www.carbike360.com. It has more than 1 Lac urls, but only 50k pages are indexed and more than 20k pages are giving crawling error.
-
the same problem with me created in the crawling process.
with my own website https://tracked.ai/Accelerated.aspx. -
These types of issues are pretty easy to detect and solve by simply checking your meta tags and robots.txt file, which is why you should look at it first. The whole website or certain pages can remain unseen by Google for a simple reason: its site crawlers are not allowed to enter them.
There are several bot commands, which will prevent page crawling. Note, that it’s not a mistake to have these parameters in robots.txt; used properly and accurately these parameters will help to save a crawl budget and give bots the exact direction they need to follow in order to crawl pages you want to be crawled.
You can detect this issue checking if your page’s code contains these directive:
<meta name="robots" content="noindex" />
<meta name="robots" content="nofollow"> -
VPS Server company in India'
Buy cheap Domain and web hosting in India with FREE domain. providing webhosting, domain registration, web designing, dedicated server, vps. Order today and get offer. Buy a domain and hosting at the lowest prices with 24x7 supports.
Got a burning SEO question?
Subscribe to Moz Pro to gain full access to Q&A, answer questions, and ask your own.
Explore more categories
-
Chat with the community about the Moz tools.
-
Discuss the SEO process with fellow marketers
-
Discuss industry events, jobs, and news!
-
Chat about tactics outside of SEO
-
Dive into research and trends in the search industry.
-
Support
Connect on product support and feature requests.
-
-
 116976
116976
-
04532
-
 071.9k
071.9k
-
 021.5k
021.5k
-
 062.5k
062.5k
-
 0224.6k
0224.6k
-
 043.7k
043.7k
-
 033.2k
033.2k