After more than 13 years, and tens of thousands of questions, Moz Q&A closed on 12th December 2024. Whilst we’re not completely removing the content - many posts will still be possible to view - we have locked both new posts and new replies. More details here.
Site Audit Tools Not Picking Up Content Nor Does Google Cache
-
Hi Guys,
Got a site I am working with on the Wix platform. However site audit tools such as Screaming Frog, Ryte and even Moz's onpage crawler show the pages having no content, despite them having 200 words+. Fetching the site as Google clearly shows the rendered page with content, however when I look at the Google cached pages, they also show just blank pages.
I have had issues with nofollow, noindex on here, but it shows the meta tags correct, just 0 content.
What would you look to diagnose? I am guessing some rogue JS but why wasn't this picked up on the "fetch as Google".
-
@nezona
DM Fitrs
Facing issues with site audit tools and Google Cache not picking up content can be a technical puzzle to solve. It's crucial to address these challenges for a smoother online presence. Similarly, in managing our digital responsibilities, like checking PESCO online bills, reliability is key. Just as we troubleshoot website-related matters, staying on top of utility payments ensures a hassle-free experience. Navigate technical hiccups, both in website diagnostics and bill management, to maintain a seamlessly connected online routine. -
Hi Team,
I am facing problem with one of my website where google is caching the page when checked using cache: operator but displaying a 404 msg in the body of the cached version.
But when i check the same in 'text-only version' the complete content and element is visible to Google and also GSC shows the page with no issue and rendering is also fine.
The canonicals and robots are properly set with no issues on them.
Not able to figure out what is the problem. Experts advice would help!Regards,
Ryan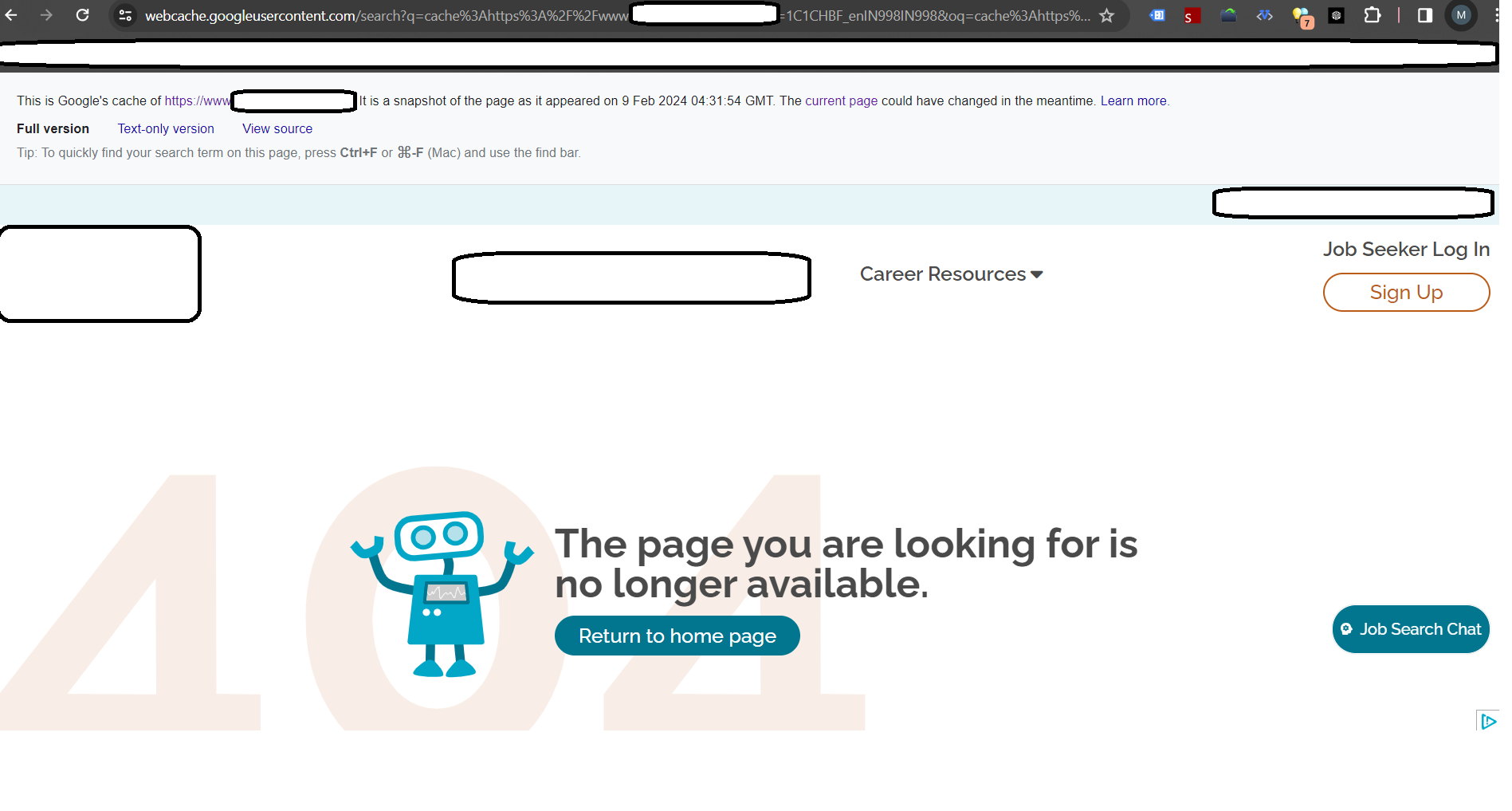
-
Hey Neil
")
Wow, we are really chuffed here at Effect Digital! I guess... we have a lot of combined experience - and we also try to give something back to the community (as well as making profit, obviously)
We didn't actually know how many people used the Moz Q&A forum until recently. It seemed like a good hub to demonstrate that, not all agency accounts have to exist to give shallow 1-liner replies from a position of complete ignorance (usually just so they can link spam the comments). Groups of people, **can **be insightful and 'to the point'
Again we're just really thrilled that you found our analysis to be useful. It also shows what goes into what we do. Most of the responses on here which are under-detailed have the potential to lead people down rabbit holes. Sometimes you just have to get into the thick of it right?
I think our email address is publicly listed on our profile page. Feel free to hit us up
-
My Friend,
That is some analysis you have done there!! and I am eternally greatful. It's people like you, who are clearly so passionate about SEO, that make our industry amazing!!
I am going to private message you a longer reply, later but i just wanted to publicly say thank you!!
Regards
Neil
-
Ok let's have a look here.
So this is the URL of the page you want me to look at:
I can immediately tell you that, from my end it doesn't look like Google has even cached this page at all:
- http://webcache.googleusercontent.com/search?q=cache:https%3A%2F%2Fwww.nubalustrades.co.uk%2F (live)
- https://d.pr/i/DhmPEr.png (screenshot)
As you know I can't fetch someone else's web page as Google, but I do know Screaming Frog pretty well so let's give that a blast
First let's try a quick crawl with no client-side rendering enabled, see what that comes back with:
- https://d.pr/f/u3bifA.seospider (SF crawl file)
- https://d.pr/f/9TfNR5.xlsx (Excel spreadsheet output)
Seems as if, even without rendered crawling the words are being picked up:
Only the rows highlighted in green (the 'core' site URLs) should have a word count anyway. The other URLs are fragments and resources. They're scripts, stylesheets, images etc (none of which need copy).
Let's try a rendered crawl, see what we get:
- https://d.pr/f/ijprbx.seospider (SF crawl file)
- https://d.pr/f/c8ljoF.xlsx (Excel spreadsheet output)
Again - it seems as if the words are picked up, though oddly fewer are picked up with rendered crawling than with a simple AJAX source scrape:
That could easily be something to do with my time-out or render-wait settings though (that being said I did give a pretty generous 23 seconds so...)
In any case, it seems to me that the content is search readable in either event.
Let's look at the homepage specifically in more detail. Basically if content appears in "inspect element" but not in "view source", **that's **when you know you have a real problem
- view-source:https://www.nubalustrades.co.uk/ - (you can only open this link with Chrome browser, it's free to download from Google)
As you can see, lots of the content does indeed appear in the 'base' source code:
That's a good thing.
That being said, each piece of content seems to be replicated twice in the source code which is really weird and may be creating some content duplication issues, if Google's more simple crawl-bots aren't taking the time to analyse the source code correctly.
Go back here:
- view-source:https://www.nubalustrades.co.uk/ - (this link only works in Chrome!)
Ctrl+F to find the string of text: "issued by the British Standards Institution". Hit enter a few times. You'll see the page jump about.
On the one hand you have this, further up the page which looks alright:
On the other hand you have this further down which looks like a complete mess, embedded within some kind of script or something?
Line 6,212 of the source code is some gigantic JavaScript thing which has been in-lined (and don't get me started on how this site is over-using inline code in general, for CSS, JS - everything). No idea what it's for or does, might be deferred stuff to boost page speed without breaking the visuals or whatever (there are many clever tricks like that, but they make the source code a virtually unreadable mess for a human - let alone a programmed bot!)
What really concerns me is why such a simple page needs to have 6,250 lines of source code. That's mental!
What we all forget is that, whilst the crawl and fetch bots pull information quickly - Google's algorithms have to be run over the top of that source code and data (which is a much more complex affair)
Usually people think that normalizing the code-to-text ratio is a pointless SEO maneuver and in most cases, yes the return is vastly outweighed by the time taken to do it. But in your case it's actually very extreme:
Put your URL in and you'll get this:
I tried like 5-8 different tools and this was the most favorable result :')
It is clear that, even were the page successfully downloaded by Google, their algorithms may have trouble hunting out the nuggets of content within the vast, sprawling and unnecessary coding structure. My older colleagues had always warned me away from Wix... now I can see why, with my own two eyes
Ok. So we know that Google isn't bothering to cache the page, and that - despite the fact your content can 'technically' be crawled, it may be a marathon to do that and dig it out (especially for non-intelligent robots)
But is the content being indexed? Let's check:
- https://www.google.co.uk/search?q=site%3Anubalustrades.co.uk+%22issued+by+the+British+Standards+Institution%22
- https://www.google.co.uk/search?num=100&ei=q_MYXMj3EM_srgSNh6LYCQ&q=site%3Anubalustrades.co.uk+%22product+and+your+happy+with%22
- https://www.google.co.uk/search?num=100&ei=6vMYXPuLC4yYsAXAoKfAAg&q=site%3Anubalustrades.co.uk+%22Some+customers+like+to+have+more+than+one+balustrade%22
- https://www.google.co.uk/search?num=100&ei=CPQYXOmJFYu6tQXi8arwBA&q=site%3Anubalustrades.co.uk+%22installations+which+will+help+you+visualise+your+future+project%22
- https://www.google.co.uk/search?num=100&ei=KvQYXMyhC4LStAWopbqACg&q=site%3Anubalustrades.co.uk+%22Cleanly-designed%2C+high-quality+handrail+systems+combined+with+attention%22
Those are all special Google search queries, designed to specifically search for strings of content on your website from all the different, primary content boxes
Good news fella, it's all being found:
Let's make up an invalid text string and see what Google returns when text can't be found, to validate our findings thus-far:
If nothing is found you get this:
So I guess Google can find your content and is indexing your content
Phew, crisis over! Onto the next one...
-
Hi There,
This is the URL:-
https://www.nubalustrades.co.uk/
Be great if you could give me your opinion. I am thinking that this content isn't being indexed.
Regards
Neil
-
If you can share a link to the site I can probably diagnose it. It's probably that the content is within the modified (client-side rendered) source code, rather than the 'base' (non-modified) source code. Google fetches pages in multiple different ways, so using fetch as Google artificially makes it seem as if they always use exactly the same crawling technology. They don't.
Google 'can' crawl modified content. But they don't always do it, and they don't do it for everyone. Rendered crawling takes like... 10x longer than basic source scraping. Their mission is to index the web!
The fetch tool shows you their best-case scenario crawling methodology. Don't assume their indexation bots, which have a mountain to climb - will always be so favourable
-
Just an update on this one
Looks like it may be a problem with Wix
https://moz.com/community/q/wix-problem-with-on-page-optimization-picking-up-seo
I have another client who also uses Wix and they also show now content in screaming frog but worryingly their pages show in a cached version of the site. I know the "cache" isn't the best way to see what content is indexed and the fetch as Google is fine.
I just get the feeling something isn't right.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Got a burning SEO question?
Subscribe to Moz Pro to gain full access to Q&A, answer questions, and ask your own.
Explore more categories
-
Chat with the community about the Moz tools.
-
Discuss the SEO process with fellow marketers
-
Discuss industry events, jobs, and news!
-
Chat about tactics outside of SEO
-
Dive into research and trends in the search industry.
-
Support
Connect on product support and feature requests.
-