Broken Links from Open Site Explorer
-
I am trying to find broken internal links within my site. I found a page that was non-existent but had a bunch of internal links pointing to that page, so I ran an Open Site Explorer report for that URL, but it's limited to 25 URLs.
Is there a way to get a report of all of my internal pages that link to this invalid URL? I tried using the link: search modifier in Google, but that shows no responses.
-
Whew! Big thread.
Sometimes, when you can't find all the broken links to a page, it's easier simply to 301 redirect the page to a destination of your choice. This helps preserve link equity, even for those broken links you can't find on large sites. (and external links, as well)
Not sure if this would help in your situation, but I hope you're getting things sorted out!
-
Jesse,
That's where I started my search, but GWMT wasn't showing this link. I can only presume that because it isn't coming back a 404 (it is showing that "We're Sorry" message instead) that they're considering that message to be content.
Thanks!
-
Lynn, that was a BIG help. I had been running that report, but was restricted to 25 responses. When I saw your suggestion to filter for only internal links, I was able to see all 127.
Big props. Thanks!
-
One more thing to add - GWMT should report all 404 links and their location/referrer.
-
oops! i did not know this. Thanks Irving.
-
Use the word FREE with an asterisk because sreaming frog is now limiting the free version to 500 pages. Xenu is better, even brokenlinkcheck.com lets you spider 3000 pages.
500 pages makes the tool practically worthless for any site of decent size.
-
Indeed if it is not showing a 404, that makes things a bit difficult!
You could try another way, use OSE!
Use the exact page, filter for only internal links, boom 127 pages that link to it. There might be more, but this should get you going!
-
Jesse:
I appreciate your feedback, but am surprised that the ScreamingFrog report found no 404s. SEOmoz found 15 in Roger's last crawl, but those aren't the ones that I'm currently trying to solve.
The problem page is actually showing up as duplicate content, which is kinda screwy. When visiting the page, our normal 404 error doesn't appear (which our developers are still trying to figure out), but instead, an error message appears:
http://www.gallerydirect.com/about-us/media-birchwood
If this were a normal 404 page, we'd probably be able to find the links faster.
-
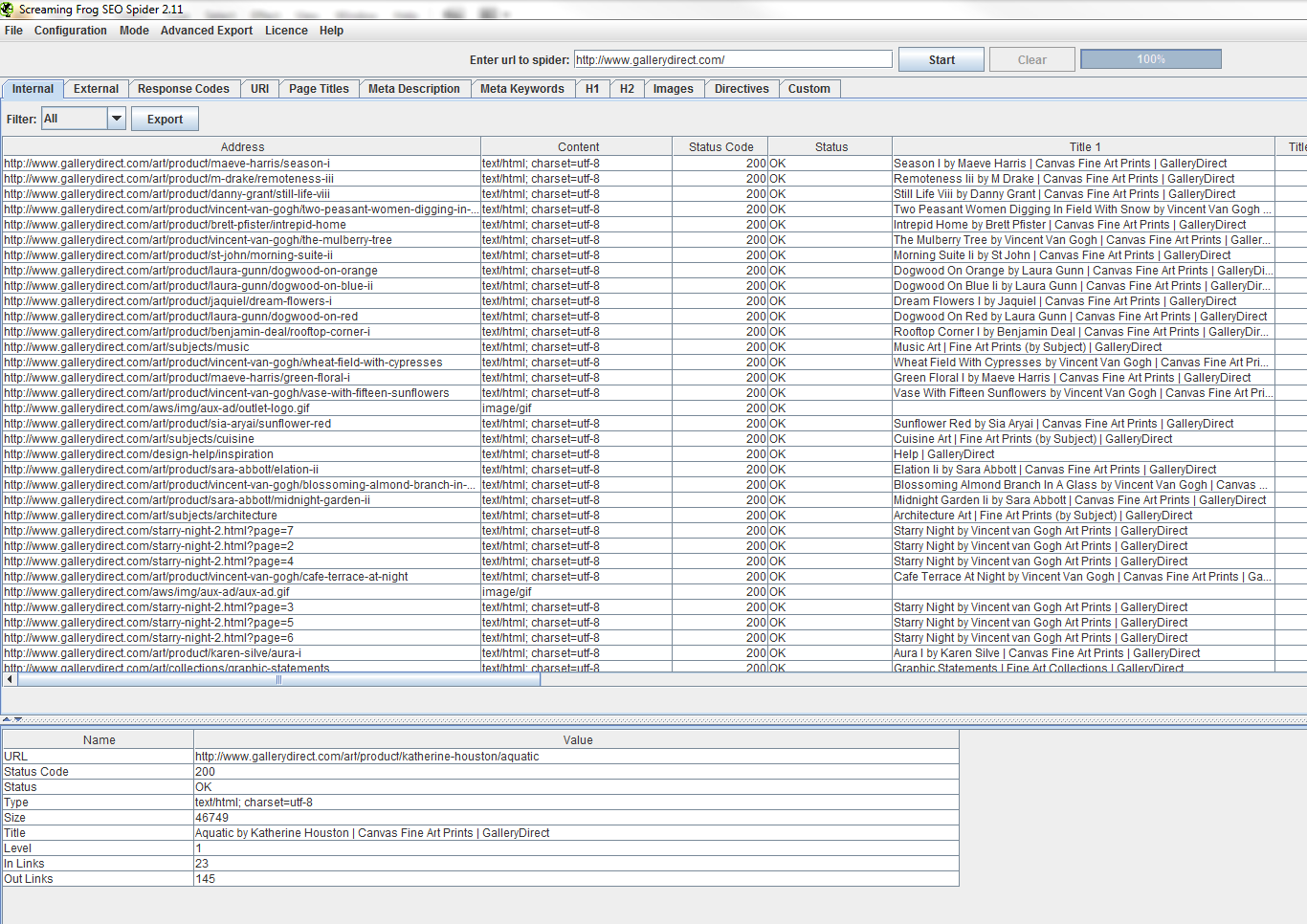
I got tired of the confusion and went ahead and proved it. Not sure if this is the site you wanted results for, but I used the site linked in your profile (www.gallerydirect.com)
took me about 90 seconds and I had a full list... no 404s though
anyway here's a screenshot to prove it:
http://gyazo.com/67b5763e30722a334f3970643798ca62.png
so what's the problem? want me to crawl the fbi site next?
-
I understand. Thing is, there is a way and the spider doesn't affect anything. Like I said, I have screaming frog installed on my computer and I could run a report for your website right now and you or your IT department would never know it happened.. I just don't understand the part where the software doesn't work for you but to each their own i suppose.
-
Jesse:
That movie was creepy, but John Goodman was awesome in it.
I started this thread because I was frustrated that OSE restricts my results to 25 links, and I simply wanted to find the rest for that particular URL. I was assuming that there was either:
a. A method for getting the rest of the links that Roger found
b. Another way of pulling these reports from someone who already spiders them (since I can't get any using the link:[URL] in Google and Webmaster Tools isn't showing them).
Thanks to all for your suggestions.
-
run the spider based app from outside their "precious network" then. hell, i could run it right now for you from my computer at work if I wanted. Use your laptop or home computer. It's a simple spider you don't have to be within any network to run it. You could run one for CNN.com if you'd like as well...
-
How else do you expect to trace these broken links without using a "spider?"
Obviously it's the solution. And the programs take up all of like 8 megs... so what's the problem/concern?
I second the screaming frog solution. It will tell you exactly what you need to know and has ZERO risk involved (or whatever it is that's hanging you up). The bazooka comparison is ridiculous, because a bazooka destroys your house. Do you really think a spider crawl will affect your website?
Spiders crawl your site and report findings. This happens often whether you download a simple piece of software or not. What do you think OSE is? Or Google?
I guess what we're saying is if you don't like the answer, then so be it. But that's the answer.
PS - OSE uses a spider to crawl your site...
PPS - Do you suffer from arachnophobia? That movie was friggin awesome now I want to watch old Jeff Daniels films.
PPSS - Do you guys remember John Goodman being in that movie? Wow the late 80s early 90s were really somethin' special.
-
John, I certainly see your point, but our IT guys would not take too kindly to me running a spider-based app from inside their precious network, which is why I was looking for a less intrusive solution.
I'm planning on a campaign to revive "flummoxed" to the everyday lexicon next.
-
Hi Darin,
Both these softwares are made for exactly this kind of job and they are not huge system killing programs or anything. Seriously I use one or both almost every day. I suggest downloading them and seeing how you go, I think you will be happy enough with the results.
-
The way I see it, its much like you missing the last flight home, and you have a choice of getting the bus, that means you might take a little longer, or of course you can wait for the next flight ,which happens to be tomorrow evening, the bus will get you home that night.
I get the bus each and every time, I get home, later than expected I grant you, but I get home a lot quicker than waiting for the plane tomorrow.
Bewildered, I didn't realise it had fallen out of the diction, its a common word (I think) in Ireland, oh and I am still young (ish)
")
-
John:
Bewildered. There's a good word that I'm happy to see someone is keeping it alive for the younger generations.
I'm not ungrateful for your suggestions, but both involve downloading and installing a spider, which seems like overkill, much like using a bazooka to kill a housefly.
-
I am bewildered by this, I have told you one, Lynn has told you another piece of free software that will do this for you.
Anyway, good luck with however you resolve our issues
-
Lynn, part of the problem is definitely template-based, and one of our developers is working on that fix now. However, I also found a number of non-template created links to this page simply due to UBD error (an old Cobol programming term meaning User Brain Dead).
I need to find all of the non-template based, UBD links that may have been created and fix them.
-
Xenu will also do a similar job and doesn't have a limit which I recall the free version of screaming frog has: http://home.snafu.de/tilman/xenulink.html
If you have loads of links to this missing page it sounds like you maybe have a template problem with the links getting inserted on every or lots of pages. In that case if you find the point in the template you will have fixed them all at once (if indeed it is like this).
-
Darin
Its a stand alone piece of software you run, it crawls your website and finds out broken inbound, outbound or internal links, tells you them ,you go and fix them

Enter your URL, be it a page or directory, run it, it will give you all bad links. And it wont limit you to 25.
You don't need to implement anything ... run the software once, use it, and well bin it afterwards if you wish
But by all means, you can do as you suggest with SE ...
Regards
John
-
John,
While I could look at implementing such a spider to run the check sitewide on a regular basis, I am not looking to go that far at the moment. For right now, I'm only looking for all of the pages on my site that link to a single incorrect URL. I would have to think that there's a solution available for such a limited search.
If I have to, I suppose I can fix the 25 that Open Site Explorer displays, wait a few days for the crawler to run again, then run the report again, fix the next 25, then so on and so on, but that's going to spread the fix out potentially over a number of weeks.
-
Free tool, non SEO Moz related
http://www.screamingfrog.co.uk/seo-spider/ , run that, will find all broken links, where they are coming from etc etc
Hope I aint braking any rules posting it
{kind=link}
Got a burning SEO question?
Subscribe to Moz Pro to gain full access to Q&A, answer questions, and ask your own.
Browse Questions
Explore more categories
-
Moz Tools
Chat with the community about the Moz tools.
-
SEO Tactics
Discuss the SEO process with fellow marketers
-
Community
Discuss industry events, jobs, and news!
-
Digital Marketing
Chat about tactics outside of SEO
-
Research & Trends
Dive into research and trends in the search industry.
-
Support
Connect on product support and feature requests.
Related Questions
-

Weird Site is linking to our site and links appears to be broken
I have got a lot of weird links indexed from this page: http://kzs.uere.info/files/images/dining-table-and-2-upholstered-chairs.html When clicking the link it shows 404. Also, the spam score is huge. What do you guys suggest to do with this?
Intermediate & Advanced SEO | | Miniorek
Could it be done by somebody to get our rankings down or domain penalized? Best Regards
Mike & Alex0 -

How to handle broken images on an old site post migration?
I am working with a client who migrated their site prior to starting their SEO work with us. In a crawl of broken backlinks, I found some old image files with links. Ideally, I would like to redirect to an appropriate image, but I have no way of knowing what the image was because the page it was on is now dead. Does anyone have a way to identify and handle broken image files from a site that has already been migrated?
Intermediate & Advanced SEO | | FPD_NYC0 -

If I nofollow outbound external links to minimize link juice loss > is it a good/bad thing?
OK, imagine you have a blog, and you want to make each blog post authoritative so you link out to authority relevant websites for reference. In this case it is two external links per blog post, one to an authority website for reference and one to flickr for photo credit. And one internal link to another part of the website like the buy-now page or a related internal blog post. Now tell me if this is a good or bad idea. What if you nofollow the external links and leave the internal link untouched so all internal links are dofollow. The thinking is this minimizes loss of link juice from external links and keeps it flowing through internal links to pages within the website. Would it be a good idea to lay off the nofollow tag and leave all as do follow? or would this be a good way to link out to authority sites but keep the link juice internal? Your thoughts are welcome. Thanks.
Intermediate & Advanced SEO | | Rich_Coffman0 -

Our site is on a secure server (https) will a link to http:// be of less value?
Our site is hosted on a secure network (I.E. Our web address is - https://www.workbooks.com). Will a backlink pointing to: http://www.workbooks.com provide less value than a link pointing to: https://www.workbooks.com ? Many thanks, Sam
Intermediate & Advanced SEO | | Sam.at.Moz0 -

Link Building
I have to develop a strategy for link building. The SEO guy I have been speaking with has started putting links on .edu sites etc . To me - this "stinks" of manipulating the search engines - which I know we will get stung by at some point. I hope this isn't standard practice - but I don't know what the best way to improve rankings in terms of links etc. We sell health products and are starting to put out 3-4 high quality articles per week. Ideas? Kind Regards Martin
Intermediate & Advanced SEO | | s_EOgi_Bear1 -

Strange situation - Started over with a new site. WMT showing the links that previously pointed to old site.
I have a client whose site was severely affected by Penguin. A former SEO company had built thousands of horrible anchor texted links on bookmark pages, forums, cheap articles, etc. We decided to start over with a new site rather than try to recover this one. Here is what we did: -We noindexed the old site and blocked search engines via robots.txt -Used the Google URL removal tool to tell it to remove the entire old site from the index -Once the site was completely gone from the index we launched the new site. The new site had the same content as the old other than the home page. We changed most of the info on the home page because it was duplicated in many directory listings. (It's a good site...the content is not overoptimized, but the links pointing to it were bad.) -removed all of the pages from the old site and put up an index page saying essentially, "We've moved" with a nofollowed link to the new site. We've slowly been getting new, good links to the new site. According to ahrefs and majestic SEO we have a handful of new links. OSE has not picked up any as of yet. But, if we go into WMT there are thousands of links pointing to the new site. WMT has picked up the new links and it looks like it has all of the old ones that used to point at the old site despite the fact that there is no redirect. There are no redirects from any pages of the old to the new at all. The new site has a similar name. If the old one was examplekeyword.com, the new one is examplekeywordcity.com. There are redirects from the other TLD's of the same to his (i.e. examplekeywordcity.org, examplekeywordcity.info), etc. but no other redirects exist. The chances that a site previously existed on any of these TLD's is almost none as it is a unique brand name. Can anyone tell me why Google is seeing the links that previously pointed to the old site as now pointing to the new? ADDED: Before I hit the send button I found something interesting. In this article from dejan SEO where someone stole Rand Fishkin's content and ranked for it, they have the following line: "When there are two identical documents on the web, Google will pick the one with higher PageRank and use it in results. It will also forward any links from any perceived ’duplicate’ towards the selected ‘main’ document." This may be what is happening here. And just to complicate things further, it looks like when I set up the new site in GA, the site owner took the GA tracking code and put it on the old page. (The noindexed one that is set up with a nofollowed link to the new one.) I can't see how this could affect things but we're removing it. Confused yet? I'd love to hear your thoughts.
Intermediate & Advanced SEO | | MarieHaynes0 -

What url should i link to?
Hi everybody, after some discussions i decided to keep my page on the old domain for better seo rankings; However, the new third level domain sounds better: poltronafraubrescia.zenucchi.it.... the question is: i'm going to recive a high value link and i don't know if i should link directly to the old adress ( www.zenucchi.it/ITA/poltrona-frau-brescia.it ) where the page is located or to the new one by making a 301 redirect to the previous. what's best? and second question what's the way to keep the page on this adress ( www.zenucchi.it/ITA/poltrona-frau-brescia.it ) but show poltronafraubrescia.zenucchi.it as url? thank you guido
Intermediate & Advanced SEO | | guidoboem0 -

Is this site legit?
http://www.gglpls.com/ is this site legit? Submit website to google + directory?
Intermediate & Advanced SEO | | SEODinosaur0