After more than 13 years, and tens of thousands of questions, Moz Q&A closed on 12th December 2024. Whilst we’re not completely removing the content - many posts will still be possible to view - we have locked both new posts and new replies. More details here.
Unsolved The Moz.com bot is overloading my server
-
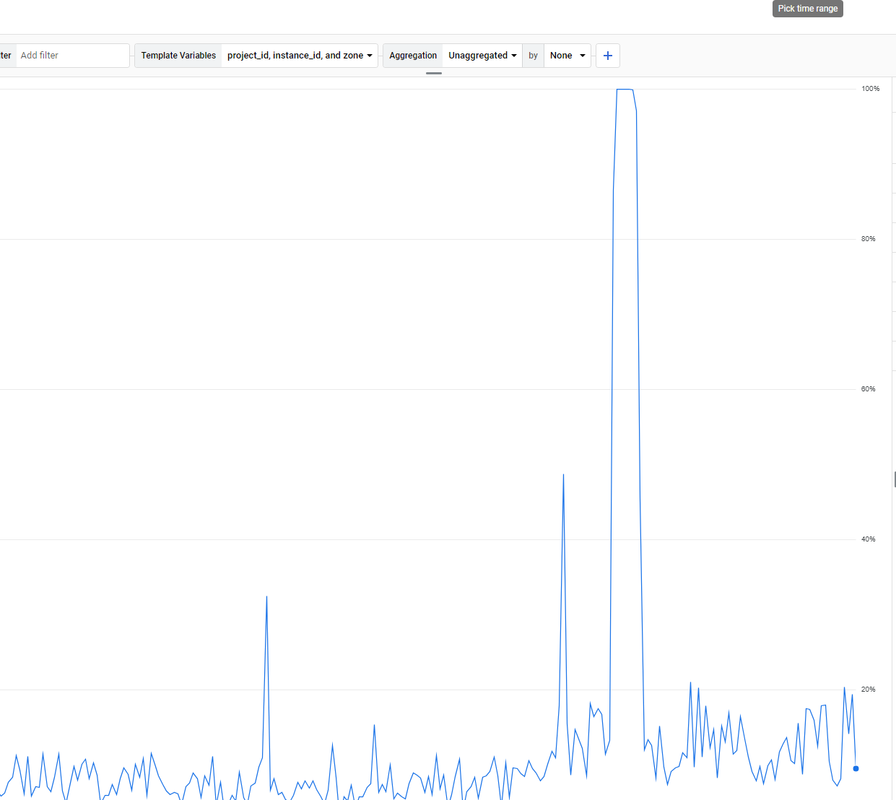 . How to solve it?
. How to solve it? -
For a step-by-step guide on setting up the tool, check out the solara executor download tutorial.
-
maybe crawl delay will help.
-
@paulavervo
Hi,
We do! The best way to chat with us is via our contact form or direct email. We also have chat within Moz Pro.
Please contact us via help@moz.com or https://moz.com/help/contact
We will be happy to help.
Cheers,
Kerry. -
very nice brother i like it very good keep it up !
-
very nice !
-
does the moz team even monitor this forum?
-
If the Moz.com bot is overloading your server, there are several steps you can take to manage and mitigate the issue effectively. First, you can adjust the crawl rate in your
robots.txtfile by specifying a crawl delay for the Moz bot using directives likeUser-agent: rogerbotandUser-agent: dotbot, followed byCrawl-delay: 10to make the bot wait 10 seconds between requests. If this does not suffice, you can temporarily block the bot by disallowing it in yourrobots.txtfile. Additionally, it's a good idea to contact Moz’s support team to explain the issue, as they may offer solutions to adjust the crawl rate for your site. Implementing server-side rate limiting is another effective strategy. For Apache servers, you can add rules in your.htaccessfile to return a 429 Too Many Requests status code to the Moz bots, while for Nginx servers, you can set up rate limiting in your configuration file to control the number of requests per second from a single user or IP address. Monitoring your server’s performance and log files can help identify specific patterns or peak times, allowing you to fine-tune your settings. Furthermore, using a Content Delivery Network (CDN) can help distribute the load by caching content and serving it from multiple locations, reducing the direct impact on your server caused by crawlers. By taking these steps, you can manage the load from the Moz.com bot and maintain your server’s stability and responsiveness.
Got a burning SEO question?
Subscribe to Moz Pro to gain full access to Q&A, answer questions, and ask your own.
Explore more categories
-
Chat with the community about the Moz tools.
-
Discuss the SEO process with fellow marketers
-
Discuss industry events, jobs, and news!
-
Chat about tactics outside of SEO
-
Dive into research and trends in the search industry.
-
Support
Connect on product support and feature requests.
-
-
 04412
04412
-
072.0k
-
 041.6k
041.6k
-
 022.8k
022.8k
-
 172.2k
172.2k
-
 082.4k
082.4k