After more than 13 years, and tens of thousands of questions, Moz Q&A closed on 12th December 2024. Whilst we’re not completely removing the content - many posts will still be possible to view - we have locked both new posts and new replies. More details here.
Screaming From occurences and canonicals what does it all mean
-
Bonjourno from Wetherby UK...
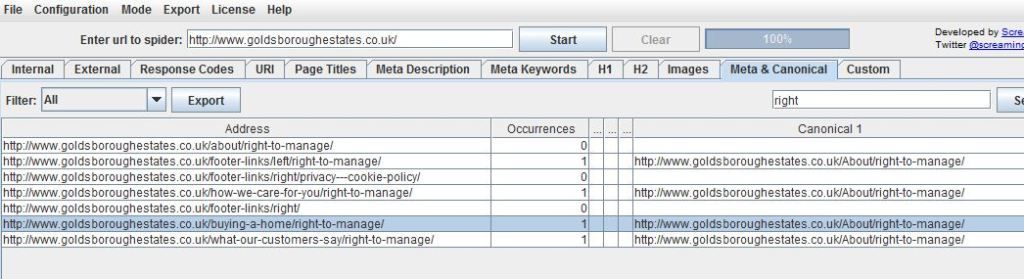
Ive used a package called screamong frog to diagnose canonical errors but can anyone tell me what this means? http://i216.photobucket.com/albums/cc53/zymurgy_bucket/understand-occurances-canonical.jpg
Thanks in advance.
David
-
Thank you for all your replies this was bugging me but the pain of not knowing has vanished like the morning mist as the warming glow of sunshine illumunates truth
")
-
David
Looks like you may have an issue there. The "address" and "canonical 1" should match about 99% of the time. Right now you're telling Google to index all those different address pages as a single URL (About/right-to-manage)... something to look at - and the suggestions below are both good as well.
-Dan
-
I agree with what Streamline Metrics said, I just want to add to this by linking you to a great SEOmoz post on canonicalization which may help you clear things up more.
In your case, having 1 rel="canonical" tag per page is what you want, so you should be fine with that, just make sure that the canonical tags (listed under canonical 1 in Screaming Frog) is the actual URL that you want.
Hope this helps
Zach -
It simply means how many canonical tags are found on that specific page. So if you had two rel=canonical tags on a page, it would say 2 occurrences. For more info, check out http://www.screamingfrog.co.uk/seo-spider/user-guide/tabs/
{kind=link}
{kind=link}
Got a burning SEO question?
Subscribe to Moz Pro to gain full access to Q&A, answer questions, and ask your own.
Explore more categories
-
Chat with the community about the Moz tools.
-
Discuss the SEO process with fellow marketers
-
Discuss industry events, jobs, and news!
-
Chat about tactics outside of SEO
-
Dive into research and trends in the search industry.
-
Support
Connect on product support and feature requests.
-