Moz Q&A is closed.
After more than 13 years, and tens of thousands of questions, Moz Q&A closed on 12th December 2024. Whilst we’re not completely removing the content - many posts will still be possible to view - we have locked both new posts and new replies. More details here.
Removing a canonical tag from Pagination pages
-
Hello,
Currently on our site we have the rel=prev/next markup for pagination along with a self pointing canonical via the Yoast Plugin. However, on page 2 of our paginated series, (there's only 2 pages currently), the canonical points to page one, rather than page 2.
My understanding is that if you use a canonical on paginated pages it should point to a viewall page as opposed to page one. I also believe that you don't need to use both a canonical and the rel=prev/next markup, one or the other will do. As we use the markup I wanted to get rid of the canonical, would this be correct?
For those who use the Yoast Plugin have you managed to get that to work?
Thanks!
-
Any resources on how to get rid of the canonical tag for those pages, and also categories and tags? I found something in Stackoverflow but I'm copying and pasting it into my header.php page and it's not working... so I feel a little clueless. Any ideas?
http://stackoverflow.com/questions/32372589/how-to-remove-rel-canonical-from-tag-pages-in-wordpress
-
Hi Jessica!
You're absolutely correct, use of a canonical on paginated pages should point to a "view all" page as opposed to page 1 of the paginated content. I've heard of the Yoast plugin causing some problems with rel=canonical markup in WP and would suggest getting rid of that canonical (especially if you have rel=prev/next markup).
Hope this helps.
B
Got a burning SEO question?
Subscribe to Moz Pro to gain full access to Q&A, answer questions, and ask your own.
Browse Questions
Explore more categories
-
Moz Tools
Chat with the community about the Moz tools.
-
SEO Tactics
Discuss the SEO process with fellow marketers
-
Community
Discuss industry events, jobs, and news!
-
Digital Marketing
Chat about tactics outside of SEO
-
Research & Trends
Dive into research and trends in the search industry.
-
Support
Connect on product support and feature requests.
Related Questions
-

Dynamic Canonical Tag for Search Results Filtering Page
Hi everyone, I run a website in the travel industry where most users land on a location page (e.g. domain.com/product/location, before performing a search by selecting dates and times. This then takes them to a pre filtered dynamic search results page with options for their selected location on a separate URL (e.g. /book/results). The /book/results page can only be accessed on our website by performing a search, and URL's with search parameters from this page have never been indexed in the past. We work with some large partners who use our booking engine who have recently started linking to these pre filtered search results pages. This is not being done on a large scale and at present we only have a couple of hundred of these search results pages indexed. I could easily add a noindex or self-referencing canonical tag to the /book/results page to remove them, however it’s been suggested that adding a dynamic canonical tag to our pre filtered results pages pointing to the location page (based on the location information in the query string) could be beneficial for the SEO of our location pages. This makes sense as the partner websites that link to our /book/results page are very high authority and any way that this could be passed to our location pages (which are our most important in terms of rankings) sounds good, however I have a couple of concerns. • Is using a dynamic canonical tag in this way considered spammy / manipulative? • Whilst all the content that appears on the pre filtered /book/results page is present on the static location page where the search initiates and which the canonical tag would point to, it is presented differently and there is a lot more content on the static location page that isn’t present on the /book/results page. Is this likely to see the canonical tag being ignored / link equity not being passed as hoped, and are there greater risks to this that I should be worried about? I can’t find many examples of other sites where this has been implemented but the closest would probably be booking.com. https://www.booking.com/searchresults.it.html?label=gen173nr-1FCAEoggI46AdIM1gEaFCIAQGYARS4ARfIAQzYAQHoAQH4AQuIAgGoAgO4ArajrpcGwAIB0gIkYmUxYjNlZWMtYWQzMi00NWJmLTk5NTItNzY1MzljZTVhOTk02AIG4AIB&sid=d4030ebf4f04bb7ddcb2b04d1bade521&dest_id=-2601889&dest_type=city& Canonical points to https://www.booking.com/city/gb/london.it.html In our scenario however there is a greater difference between the content on both pages (and booking.com have a load of search results pages indexed which is not what we’re looking for) Would be great to get any feedback on this before I rule it out. Thanks!
Technical SEO | | GAnalytics1 -

Getting rid of pagination - redirect all paginated pages or leave them to 404?
Hi all, We're currently in the process of updating our website and we've agreed that one of the things we want to do is get rid of all our pagination (currently used on the blog and product review areas) and instead implement load more on scroll. The question I have is... should we redirect all of the paginated pages and if so, where to? (My initial thoughts were either to the blog homepage or to the archive page) OR do we leave them to just 404? Bear in mind we have thousands of paginated pages 😕 Here's our blog area btw - https://www.ihasco.co.uk/blog Any help would be appreciated, thanks!
Technical SEO | | iHasco0 -

Do URLs with canonical tags get indexed by Google?
Hi, we re-branded and launched a new website in February 2016. In June we saw a steep drop in the number of URLs indexed, and there have continued to be smaller dips since. We started an account with Moz and found several thousand high priority crawl errors for duplicate pages and have since fixed those with canonical tags. However, we are still seeing the number of URLs indexed drop. Do URLs with canonical tags get indexed by Google? I can't seem to find a definitive answer on this. A good portion of our URLs have canonical tags because they are just events with different dates, but otherwise the content of the page is the same.
Technical SEO | | zasite0 -

Does Title Tag location in a page's source code matter?
Currently our meta description is on line 8 for our page - http://www.paintball-online.com/Paintball-Guns-And-Markers-0Y.aspx
Technical SEO | | Istoresinc The title tag, however sits below a bunch of code on line 237
The title tag, however sits below a bunch of code on line 237
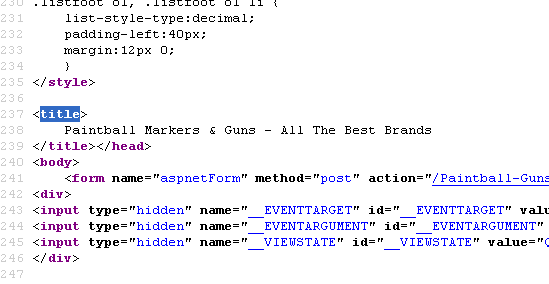 Does the location of the title tag, meta tags, and any structured data have any influence with respect to SEO and search engines? Put another way, could we benefit from moving the title tag up to the top?
I "surfed 'n surfed" and could not find any articles about this.
I would really appreciate any help on this as our site got decimated organically last May and we are looking for any help with SEO.
NIck
0
Does the location of the title tag, meta tags, and any structured data have any influence with respect to SEO and search engines? Put another way, could we benefit from moving the title tag up to the top?
I "surfed 'n surfed" and could not find any articles about this.
I would really appreciate any help on this as our site got decimated organically last May and we are looking for any help with SEO.
NIck
0 -

Product Pages Outranking Category Pages
Hi, We are noticing an issue where some product pages are outranking our relevant category pages for certain keywords. For a made up example, a "heavy duty widgets" product page might rank for the keyword phrase Heavy Duty Widgets, instead of our Heavy Duty Widgets category page appearing in the SERPs. We've noticed this happening primarily in cases where the name of the product page contains an at least partial match for the desired keyword phrase we want the category page to rank for. However, we've also found isolated cases where the specified keyword points to a completely irrelevent pages instead of the relevant category page. Has anyone encountered a similar issue before, or have any ideas as to what may cause this to happen? Let me know if more clarification of the question is needed. Thanks!
Technical SEO | | ShawnHerrick0 -

Handling 301s: Multiple pages to a single page (consolidation)
Been scouring the interwebs and haven't found much information on redirecting two serparate pages to a single new page. Here is what it boils down to: Let's say a website has two pages, both with good page authority of products that are becoming fazed out. The products, Widget A and Widget B, are still popular search terms, but they are being combined into ONE product, Widget C. While Widget A and Widget B STILL have plenty to do with Widget C, Widget C is now the new page, the main focus page, and the page you want everyone to see and Google to recognize. Now, do I 301 Widget A and Widget B pages to Widget C, ALTHOUGH Widgets A and B previously had nothing to do with one another? (Remember, we want to try and keep some of that authority the two page have had.) OR do we keep Widget A and Widget B pages "alive", take them off the main navigation, and then put a "disclaimer" on the pages announcing they are now part of Widget C and link to Widget C? OR Should Widgets A and B page be canonicalized to Widget C? Again, keep in mind, widgets A and B previously were not similar, but NOW they are and result in Widget C. (If you are confused, we can provide a REAL work example of what we are talkinga about, but decided to not be specific to our industry for this.) Appreciate any and all thoughts on this.
Technical SEO | | JU19850 -

Do I need to add canonical link tags to pages that I promote & track w/ UTM tags?
New to SEOmoz, loving it so far. I promote content on my site a lot and am diligent about using UTM tags to track conversions & attribute data properly. I was reading earlier about the use of link rel=canonical in the case of duplicate page content and can't find a conclusive answer whether or not I need to add the canonical tag to these pages. Do I need the canonical tag in this case? If so, can the canonical tag live in the HEAD section of the original / base page itself as well as any other URLs that call that content (that have UTM tags, etc)? Thank you.
Technical SEO | | askotzko1 -

What's the difference between a category page and a content page
Hello, Little confused on this matter. From a website architectural and content stand point, what is the difference between a category page and a content page? So lets say I was going to build a website around tea. My home page would be about tea. My category pages would be: White Tea, Black Tea, Oolong Team and British Tea correct? ( I Would write content for each of these topics on their respective category pages correct?) Then suppose I wrote articles on organic white tea, white tea recipes, how to brew white team etc...( Are these content pages?) Do I think link FROM my category page ( White Tea) to my ( Content pages ie; Organic White Tea, white tea receipes etc) or do I link from my content page to my category page? I hope this makes sense. Thanks, Bill
Technical SEO | | wparlaman0