Duplicate content homepage - Google canonical 'N/A'?
-
Hi,
I redesigned a clients website and launched it two weeks ago. Since then, I have 301 redirected all old URL's in Google's search results to their counterparts on the new site.
However, none of the new pages are appearing in the search results and even the homepage has disappeared. Only old site links are appearing (even though the old website has been taken down ) and in GSC, it's stating that:
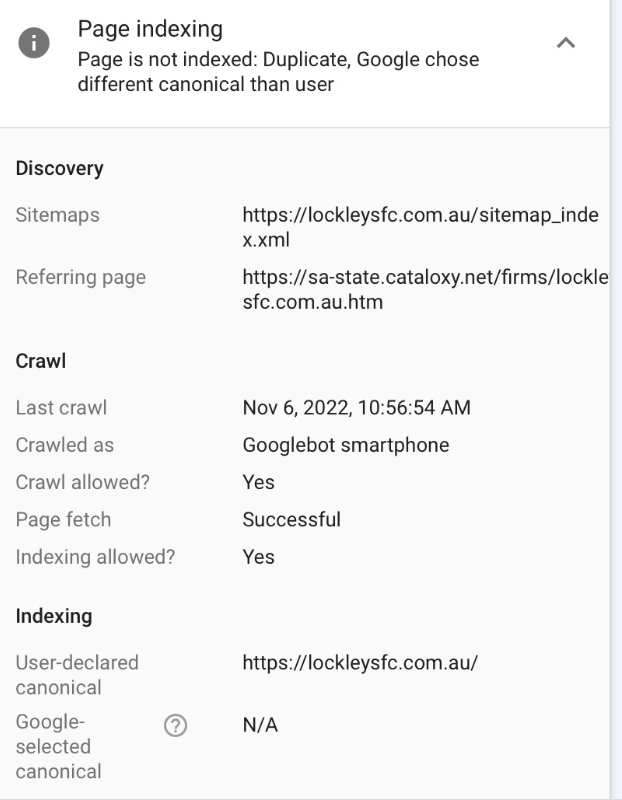
Page is not indexed: Duplicate, Google chose different canonical than user
However, when I try to understand how to fix the issue and see which URL it is claiming to be a duplicate of, it says:
Google-selected canonical: N/A
It says that the last crawl was only yesterday - how can I possibly fix it without knowing which page it says it's a duplicate of? Is this something that just takes time, or is it permanent?
I would understand if it was just Google taking time to crawl the pages and index but it seems to be adamant it's not going to show any of them at all.
-
The contradictory GSC report is curious. My guess without more info is that either Google has not found the redirect, or cannot see the redirect.
When I checked some pages myself e.g. https://sa-state.cataloxy.net/firms/adelaide-airport.htm, they are not redirected. Is this intentional?
Got a burning SEO question?
Subscribe to Moz Pro to gain full access to Q&A, answer questions, and ask your own.
Browse Questions
Explore more categories
-
Moz Tools
Chat with the community about the Moz tools.
-
SEO Tactics
Discuss the SEO process with fellow marketers
-
Community
Discuss industry events, jobs, and news!
-
Digital Marketing
Chat about tactics outside of SEO
-
Research & Trends
Dive into research and trends in the search industry.
-
Support
Connect on product support and feature requests.
Related Questions
-

Strange - Search Console page indexing "../Detected" as 404
Anyone seen this lately? All of a sudden Google Search Console is insisting in Page indexing that there is a 404 for a page that has never existed on our client's site: https://........com.au/Detected We've noticed this across a number of sites, precisely in this way with a capitalised "/Detected" To me it looks like something spammy is being submitted to the SERPs (somehow) and Google is trying to index that and then getting a 404. Naturally MOZ isn't picking it up, cause the page simply never existed - it's just happening in Search Console 2afc7e35-71e4-4e25-80a3-690bf10776a7.png It comes and it goes in the 404 alerts in Console and is really annoying. I reckon it started happening late 2022.
Reporting & Analytics | | DanielDL0 -

Google Not Indexing Pages (Wordpress)
Hello, recently I started noticing that google is not indexing our new pages or our new blog posts. We are simply getting a "Discovered - Currently Not Indexed" message on all new pages. When I click "Request Indexing" is takes a few days, but eventually it does get indexed and is on Google. This is very strange, as our website has been around since the late 90's and the quality of the new content is neither duplicate nor "low quality". We started noticing this happening around February. We also do not have many pages - maybe 500 maximum? I have looked at all the obvious answers (allowing for indexing, etc.), but just can't seem to pinpoint a reason why. Has anyone had this happen recently? It is getting very annoying having to manually go in and request indexing for every page and makes me think there may be some underlying issues with the website that should be fixed.
Technical SEO | | Hasanovic1 -

Google Search Console - Excluded Pages and Multiple Properties
I have used Moz to identify keywords that are ideal for my website and then I optimized different pages for those keywords, but unfortunately rankings for some of the pages have declined. Since I am working with an ecommerce site, I read that having a lot of Excluded pages on the Google Search Console was to be expected so I initially ignored them. However, some of the pages I was trying to optimize are listed there, especially under the 'Crawled - currently not indexed' and the 'Discovered - currently not indexed' sections. I have read this page (link: https://moz.com/blog/crawled-currently-not-indexed-coverage-status ) and plan on focusing on Steps 5 & 7, but wanted to ask if anyone else has had experience with these issues. Also, does anyone know if having multiple properties (https vs http, www vs no www) can negatively affect a site? For example, could a sitemap from one property overwrite another? Would removing one property from the Console have any negative impact on the site? I plan on asking these questions on a Google forum, but I wanted to add it to this post in case anyone here had any insights. Thank you very much for your time,
SEO Tactics | | ForestGT
Forest0 -

Unsolved Almost every new page become Discovered - currently not indexed
Almost every new page that I create becomes Discovered - currently not indexed. It started a couple of months ago, before that all pages were indexed within a couple of weeks. Now there are pages that have not been indexed since the beginning of September. From a technical point of view, the pages are fine and acceptable for a Google bot. The pages are in the sitemap and have content. Basically, these are texts of 1000+ or 2000+ words. I've tried adding new content to pages and even transferring content to a new page with a different url. But in this way, I managed to index only a couple of pages. Has anyone encountered a similar problem?
Product Support | | roadlexx
Could it be that until September of this year, I hadn't added new content to the site for several months?
Please help, I am already losing my heart.0 -

Duplicate content: using the robots meta tag in conjunction with the canonical tag?
We have a WordPress instance on an Apache subdomain (let's say it's blog.website.com) alongside our main website, which is built in Angular. The tech team is using Akamai to do URL rewrites so that the blog posts appear under the main domain (website.com/more-keywords/here). However, due to the way they configured the WordPress install, they can't do a wildcard redirect under htaccess to force all the subdomain URLs to appear as subdirectories, so as you might have guessed, we're dealing with duplicate content issues. They could in theory do manual 301s for each blog post, but that's laborious and a real hassle given our IT structure (we're a financial services firm, so lots of bureaucracy and regulation). In addition, due to internal limitations (they seem mostly political in nature), a robots.txt file is out of the question. I'm thinking the next best alternative is the combined use of the robots meta tag (no index, follow) alongside the canonical tag to try to point the bot to the subdirectory URLs. I don't think this would be unethical use of either feature, but I'm trying to figure out if the two would conflict in some way? Or maybe there's a better approach with which we're unfamiliar or that we haven't considered?
Technical SEO | | prasadpathapati0 -
Duplicate Content - Different URLs and Content on each
Seeing a lot of duplicate content instances of seemingly unrelated pages. For instance, http://www.rushimprint.com/custom-bluetooth-speakers.html?from=topnav3 is being tracked as a duplicate of http://www.rushimprint.com/custom-planners-diaries.html?resultsperpg=viewall. Does anyone else see this issue? Is there a solution anyone is aware of?
Technical SEO | | ClaytonKendall0 -

Duplicate Content
Crawl Diagnostics has returned several issues that I'm unsure how to fix. I'm guessing it's a canonical link issue but not entirely sure... Duplicate Page Content/Titles On a website (http://www.smselectronics.co.uk/market-sectors) with 6 market sectors but each pull the same 3 pages as child pages - certifications, equipment & case studies. On each products section where the page only shows X amount of items but there are several pages to fit all the products this creates multiple pages. There is also a similar pagination problem with the Blogs (auto generated date titles & user created SEO titles) & News listings. Blog Tags also seem to generate duplicate pages with the same content/titles as the parent page. Are these particularly important for SEO or is it more important to remove the duplication by deleting them? Any help would be greatly appreciated. Thanks
Technical SEO | | BBDCreative0 -

Duplicate content
I am getting flagged for duplicate content, SEOmoz is flagging the following as duplicate: www.adgenerator.co.uk/ www.adgenerator.co.uk/index.asp These are obviously meant to be the same path so what measures do I take to let the SE's know that these are to be considered the same page. I have used the canonical meta tag on the Index.asp page.
Technical SEO | | IPIM0