After more than 13 years, and tens of thousands of questions, Moz Q&A closed on 12th December 2024. Whilst we’re not completely removing the content - many posts will still be possible to view - we have locked both new posts and new replies. More details here.
Sudden Drop in Mobile Core Web Vitals
-
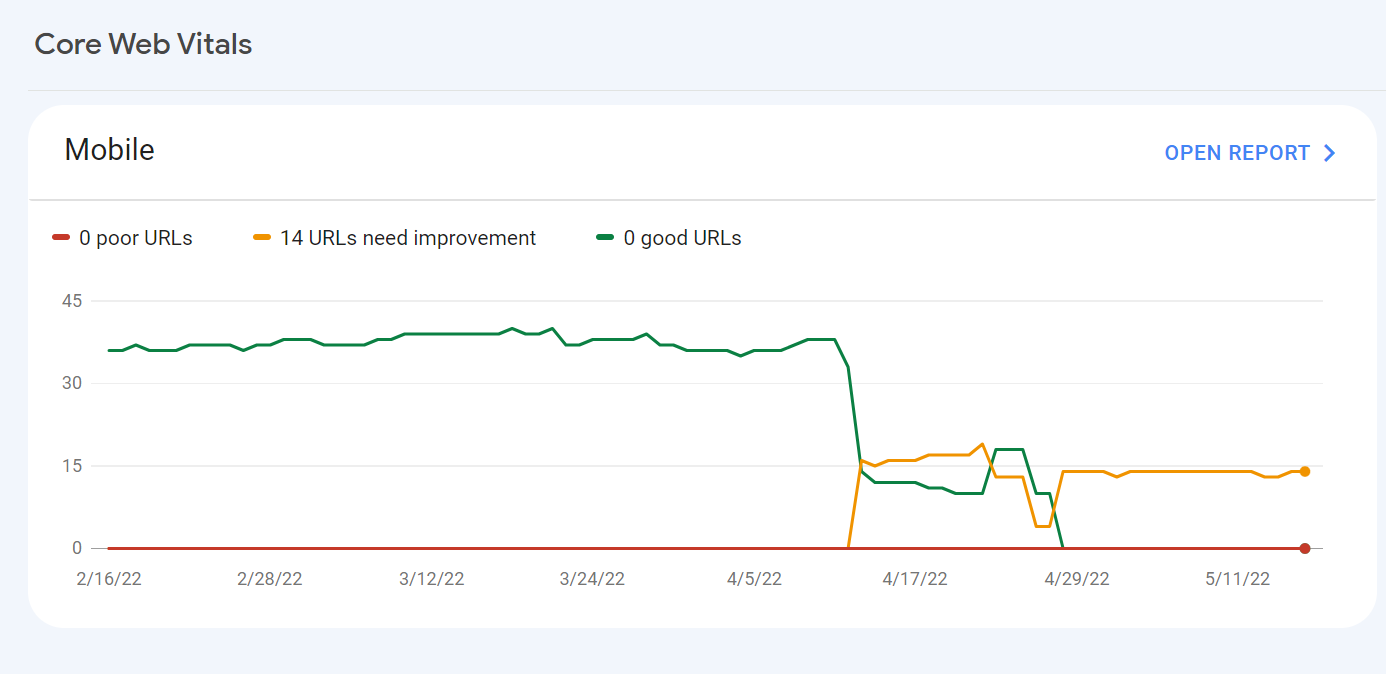
For some reason, after all URLs being previously classified as Good, our Mobile Web Vitals report suddenly shifted to the above, and it doesn't correspond with any site changes on our end.
Has anyone else experience something similar or have any idea what might have caused such a shift?
Curiously I'm not seeing a drop in session duration, conversion rate etc. for mobile traffic despite the seemingly sudden change.
-
I can’t understand their algorithm for core web vitals. I have made some technical updates to our website for speed optimization, but the thing that happened in the search console is very confusing for my site.
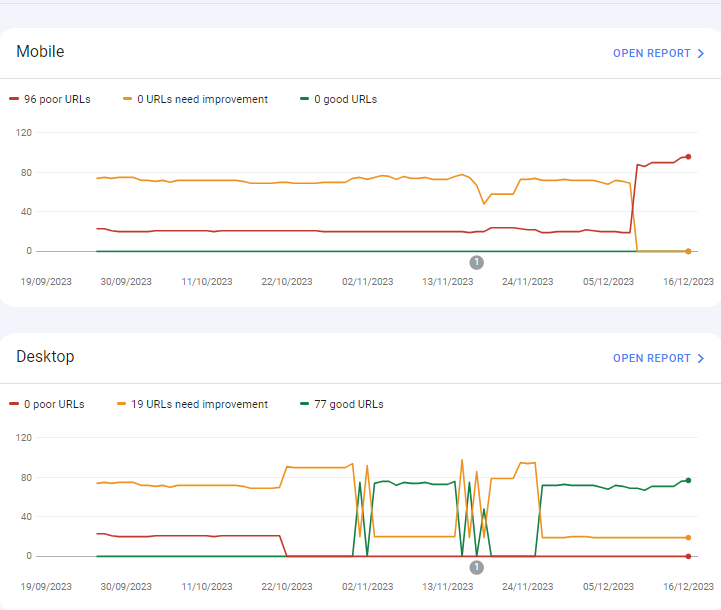
For desktops, pages are indexed as good URLs
while mobile-indexed URLs are displayed as poor URLs.
Our website is the collective material for people looking for Canada immigration (PAIC), and 70% of the portion is filled with text only. We are using webp images for optimization, still it is not passing Core Web Vitals.I am looking forward to the expert’s suggestion to overcome this problem.
-
I can’t understand their algorithm for core web vitals. I have made some technical updates to our website for speed optimization, but the thing that happened in the search console is very confusing for my site.
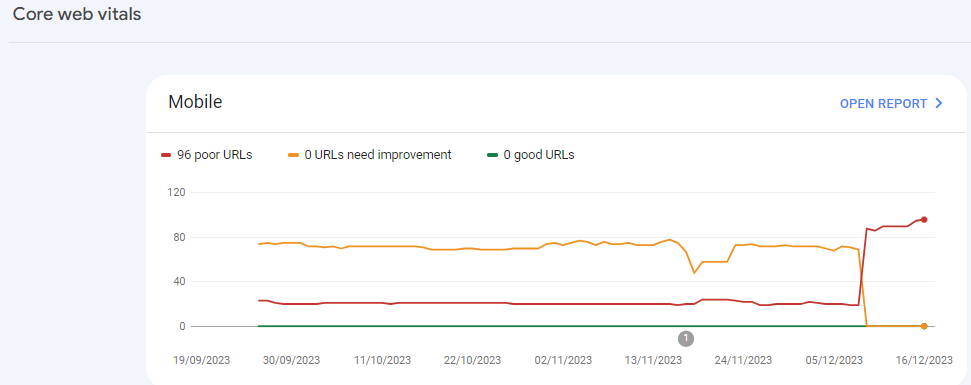
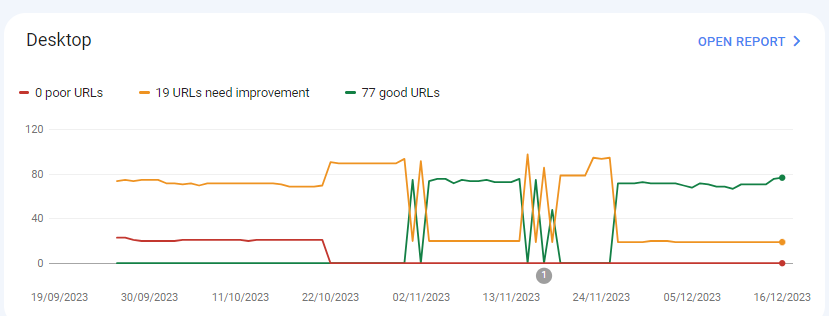
For desktops, pages are indexed as good URLs
while mobile-indexed URLs are displayed as poor URLs.
Our website is the collective material for people looking for Canadian immigration (PAIC), and 70% of the portion is filled with text only. We are using webp images for optimization, still it is not passing Core Web Vitals.I am looking forward to the expert’s suggestion to overcome this problem.
-
@rwat Hi, did you find a solution?
-
Yes, I am also experiencing the same for one of my websites, but most of them are blog posts and I am using a lot of images without proper optimization, so that could be the reason. but not sure.
It is also quite possible that Google maybe adding some more parameters to their main web critical score.
Got a burning SEO question?
Subscribe to Moz Pro to gain full access to Q&A, answer questions, and ask your own.
Explore more categories
-
Chat with the community about the Moz tools.
-
Discuss the SEO process with fellow marketers
-
Discuss industry events, jobs, and news!
-
Chat about tactics outside of SEO
-
Dive into research and trends in the search industry.
-
Support
Connect on product support and feature requests.
-
-
 091.3k
091.3k
-
 021.3k
021.3k
-
 072.8k
072.8k
-
 084.4k
084.4k
-
 1104.5k
1104.5k
-
 073.6k
073.6k
-
 123.0k
123.0k
-
 012.9k
012.9k