Moz Q&A is closed.
After more than 13 years, and tens of thousands of questions, Moz Q&A closed on 12th December 2024. Whilst we’re not completely removing the content - many posts will still be possible to view - we have locked both new posts and new replies. More details here.
Adding 'NoIndex Meta' to Prestashop Module & Search pages.
-
Hi
Looking for a fix for the PrestaShop platform
Look for the definitive answer on how to best stop the indexing of PrestaShop modules such as "send to a friend", "Best Sellers" and site search pages.
We want to be able to add a meta noindex ()to pages ending in:
/search?tag=ball&p=15 or /modules/sendtoafriend/sendtoafriend-form.php
We already have in the robot text:
Disallow: /search.php
Disallow: /modules/(Google seems to ignore these)
But as a further tool we would like to incude the noindex to all these pages too to stop duplicated pages. I assume this needs to be in either the head.tpl or the .php file of each PrestaShop module.?
Or is there a general site wide code fix to put in the metadata to apply' Noindex Meta' to certain files.
Current meta code here:
Please reply with where to add code and what the code should be.
Thanks in advance.
-
I'd implement canonical tags for your duplicate content problem instead of noindex tags. This is the recommended practice for duplicate content.
As far as pages that you don't want indexed, when you use robots.txt to accomplish this, Google can/will still put the URL & title in SERPS. In order to stop this, you do need to put meta noindex tags on every page.
Got a burning SEO question?
Subscribe to Moz Pro to gain full access to Q&A, answer questions, and ask your own.
Browse Questions
Explore more categories
-
Moz Tools
Chat with the community about the Moz tools.
-
SEO Tactics
Discuss the SEO process with fellow marketers
-
Community
Discuss industry events, jobs, and news!
-
Digital Marketing
Chat about tactics outside of SEO
-
Research & Trends
Dive into research and trends in the search industry.
-
Support
Connect on product support and feature requests.
Related Questions
-

Page disappears from Google search results
Hi, I recently encountered a very strange problem.
Technical SEO | | JoelssonMedia
One of the pages I published in my website ranked very well for a couple of days on top 5, then after a couple of days, the page completely vanished, no matter how direct I search for it, does not appear on the results, I check GSC, everything seems to be normal, but when checking Google analytics, I find it strange that there is no data on the page since it disappeared and it also does not show up on the 'active pages' section no matter how many different computers i keep it open. I have checked to page 9, and used a couple of keyword tools and it appears nowhere! It didn't have any back links, but it was unique and high quality. I have checked on the page does still exist and it is still readable. Has this ´happened to anyone before? Any thoughts would be gratefully received.0 -

Can I still monitor noindex, nofollow pages with Google Analytics?
I have a private/login site where all pages are noindex, nofollow. Can I still monitor external site links with Google Analytics?
Technical SEO | | jasmine.silver0 -

Category URL Pagination where URLs don't change between pages
Hello, I am working on an e-commerce site where there are categories with multiple pages. In order to avoid pagination issues I was thinking of using rel=next and rel=prev and cannonical tags. I noticed a site where the URL doesn't change between pages, so whether you're on page 1,2, or 3 of the same category, the URL doesn't change. Would this be a cleaner way of dealing with pagination?
Technical SEO | | whiteonlySEO0 -

Should I disavow links from pages that don't exist any more
Hi. Im doing a backlinks audit to two sites, one with 48k and the other with 2M backlinks. Both are very old sites and both have tons of backlinks from old pages and websites that don't exist any more, but these backlinks still exist in the Majestic Historic index. I cleaned up the obvious useless links and passed the rest through Screaming Frog to check if those old pages/sites even exist. There are tons of link sending pages that return a 0, 301, 302, 307, 404 etc errors. Should I consider all of these pages as being bad backlinks and add them to the disavow file? Just a clarification, Im not talking about l301-ing a backlink to a new target page. Im talking about the origin page generating an error at ping eg: originpage.com/page-gone sends me a link to mysite.com/product1. Screamingfrog pings originpage.com/page-gone, and returns a Status error. Do I add the originpage.com/page-gone in the disavow file or not? Hope Im making sense 🙂
Technical SEO | | IgorMateski0 -

Does Title Tag location in a page's source code matter?
Currently our meta description is on line 8 for our page - http://www.paintball-online.com/Paintball-Guns-And-Markers-0Y.aspx
Technical SEO | | Istoresinc The title tag, however sits below a bunch of code on line 237
The title tag, however sits below a bunch of code on line 237
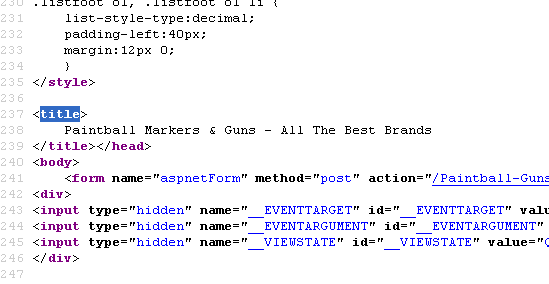 Does the location of the title tag, meta tags, and any structured data have any influence with respect to SEO and search engines? Put another way, could we benefit from moving the title tag up to the top?
I "surfed 'n surfed" and could not find any articles about this.
I would really appreciate any help on this as our site got decimated organically last May and we are looking for any help with SEO.
NIck
0
Does the location of the title tag, meta tags, and any structured data have any influence with respect to SEO and search engines? Put another way, could we benefit from moving the title tag up to the top?
I "surfed 'n surfed" and could not find any articles about this.
I would really appreciate any help on this as our site got decimated organically last May and we are looking for any help with SEO.
NIck
0 -

The word 'shop' in a page title
I'm reworking most of the page titles on our site and I'm considering the use of the word 'Shop' before a product category. ex. Shop 'keyword' | Brand Name As opposed to just using the keyword sans 'Shop.' Some of the keywords are very generic, especially for a top level category page. Question: Is the word 'Shop' damaging my SEO efforts in any way?
Technical SEO | | rhoadesjohn0 -

Should I nofollow search results pages
I have a customer site where you can search for products they sell url format is: domainname/search/keywords/ keywords being what the user has searched for. This means the number of pages can be limitless as the client has over 7500 products. or should I simply rel canonical the search page or simply no follow it?
Technical SEO | | spiralsites0 -

404 error - but I can't find any broken links on the referrer pages
Hi, My crawl has diagnosed a client's site with eight 404 errors. In my CSV download of the crawl, I have checked the source code of the 'referrer' pages, but can't find where the link to the 404 error page is. Could there be another reason for getting 404 errors? Thanks for your help. Katharine.
Technical SEO | | PooleyK0