Moz Q&A is closed.
After more than 13 years, and tens of thousands of questions, Moz Q&A closed on 12th December 2024. Whilst we’re not completely removing the content - many posts will still be possible to view - we have locked both new posts and new replies. More details here.
How to stop Google crawling after 301 redirect?
-
I have removed all pages from my old website and set 301 redirect to new website. But, I have verified old website with Google webmaster tools' HTML verification file which enable me to track all data and existence of pages in Google search for my old website. I was assumed that, Google will stop crawling and DE-indexed all pages after 301 redirect. Because, I have set 301 redirect before 3 months.
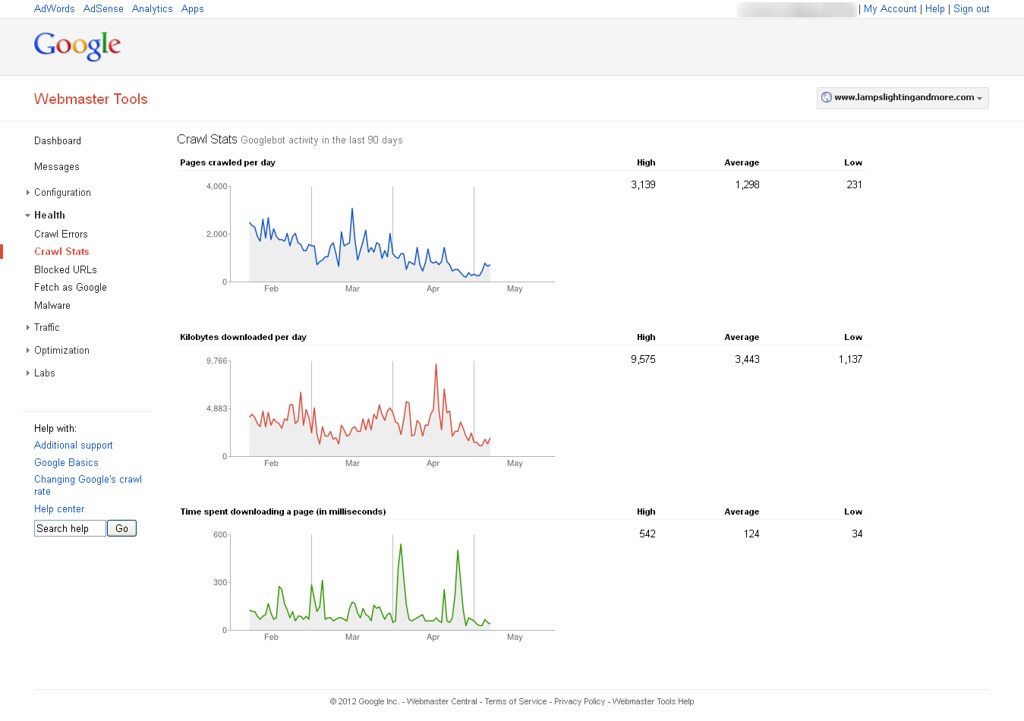
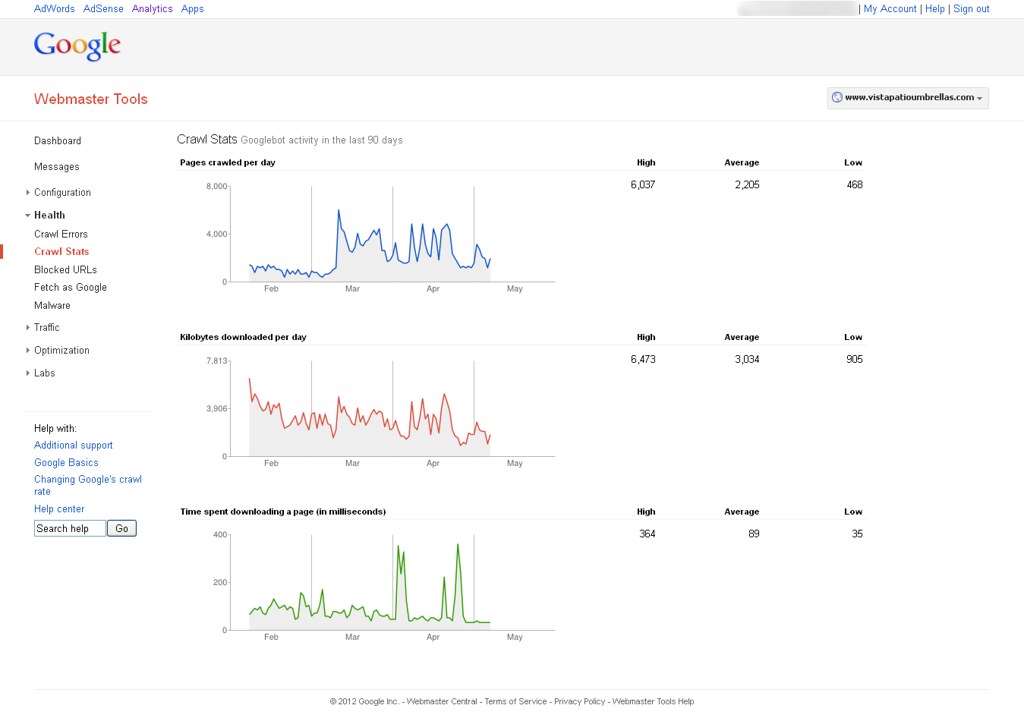
Now, I'm able to see Google bot activity on my website with help of Google webmaster tools. You can find out attachment to know more about it. How can it possible & How Google can crawl removed pages?
You can see following image to know more about it.
&
-
Google is most likely following links on other sites pointing to your old site and then 301'ing to the new site so you're seeing activity in WMT
looking here is still see two pages in the index:
you can go in and remove the site in WMT using the remove URL tool and see if that stops activity in that old WMT account. Crawling or not crawling, reporting or not reporting, there is not an issue here though - the 301's appear to be properly set up.
{kind=link}
{kind=link}
Got a burning SEO question?
Subscribe to Moz Pro to gain full access to Q&A, answer questions, and ask your own.
Browse Questions
Explore more categories
-
Moz Tools
Chat with the community about the Moz tools.
-
SEO Tactics
Discuss the SEO process with fellow marketers
-
Community
Discuss industry events, jobs, and news!
-
Digital Marketing
Chat about tactics outside of SEO
-
Research & Trends
Dive into research and trends in the search industry.
-
Support
Connect on product support and feature requests.
Related Questions
-

Is there any benefit to changing 303 redirects to 301?
A year ago I moved my marketplace website from http to https. I implemented some design changes at the same time, and saw a huge drop in traffic that we have not recovered from. I've been searching for reasons for the organic traffic decline and have noticed that the redirects from http to https URLs are 303 redirects. There's little information available about 303 redirects but most articles say they don't pass link juice. Is it worth changing them to 301 redirects now? Are there risks in making such a change a year later, and is it likely to have any benefits for rankings?
Intermediate & Advanced SEO | | MAdeit0 -

Does removal of internal redirects(301) help in SEO
I am planning to completely remove 301 redirects manually by replacing such links with actual live pages/links. So there will be no redirects internally in the website. Will this boost our SEO efforts? Auto redirects will be there for incoming links to non-existing pages. Thanks, Satish
Intermediate & Advanced SEO | | vtmoz0 -

301 redirects Ruby on Rails
Can anyone point me to the best way to implement 301 redirects on a Ruby on Rails website?
Intermediate & Advanced SEO | | brianvest0 -

Prevent Google from crawling Ajax
With Google figuring out how to make Ajax and JS more searchable/indexable, I am curious on thoughts or techniques to prevent this. Here's my Situation, we have a page that we do not ever want to be indexed/crawled or other. Currently we have the nofollow/noindex command, but due to technical changes for our site the method in which this information is being implemented if it is ever displayed it will not have the ability to block the content from search. It is also the decision of the business to not list the file in robots.txt due to the sensitivity of the content. Basically, this content doesn't exist unless something super important happens, and even if something super important happens, we do not want Google to know of its existence. Since the Dev team is planning on using Ajax/JS to pull in this content if the business turns it on, the concern is that it will be on the homepage and Google could index it. So the questions that I was asked; if Google can/does index, how long would that piece of content potentially appear in the SERPs? Can we block Google from caring about and indexing this section of content on the homepage? Sorry for the vagueness of this question, it's very sensitive in nature and I am trying to avoid too many specifics. I am able to discuss this in a more private way if necessary. Thanks!
Intermediate & Advanced SEO | | Shawn_Huber0 -

For how long does Google honor a 302 redirect?
Greetings! I would love some recent experiences to support our experience which is +/- 1 year old on this question. Based on our experiences around a year ago, I believe that Google will only honor a 302 temporary redirect for a relatively short period - perhaps up to a month - and then it will begin treating the redirect as a 301 redirect and will remove the old page from the index. Have others seen this? Is there an update on what the max "safe" period to have a 302 in place could be? We have a domain that is soon to experience about 3 months of "downtime" with no content on it, but the content will be back after that time. Ideally we would 302 redirect the pages elsewhere just for that downtime period. However, I don't want to do a 302 redirect if there is a risk that the pages will lose all of their accumulated authority and indexing. Basically, is there any safe way to just put the domain on ice for a few months? Please share recent experience only. Thanks for your insights!
Intermediate & Advanced SEO | | g-s-m0 -

Multiple 301 redirects for a HTTPS URL. Good or bad?
I'm working on an ecommerce website that has a few snags and issues with it's coding. They're using https, and when you access the website through domain.com, theres a 301 redirect to http://www.domain.com and then this, in turn, redirected to https://www.domain.com. Would this have a deterimental effect or is that considered the best way to do it. Have the website redirect to http and then all http access is redirected to the https URL? Thanks
Intermediate & Advanced SEO | | jasondexter0 -

Can an incorrect 301 redirect or .htaccess code cause 500 errors?
Google Webmaster Tools is showing the following message: _Googlebot couldn't access the contents of this URL because the server had an internal error when trying to process the request. These errors tend to be with the server itself, not with the request. _ Before I contact the person who manages the server and hosting (essentially asking if the error is on his end) is there a chance I could have created an issue with an incorrect 301 redirect or other code added to .htaccess incorrectly? Here is the 301 redirect code I am using in .htaccess: RewriteEngine On RewriteCond %{THE_REQUEST} ^[A-Z]{3,9}\ /([^/.]+/)*(index.html|default.asp)\ HTTP/ RewriteRule ^(([^/.]+/)*)(index|default) http://www.example.com/$1 [R=301,L] RewriteCond %{HTTP_HOST} !^(www.example.com)?$ [NC] RewriteRule (.*) http://www.example.com/$1 [R=301,L] Could adding the following code after that in the .htaccess potentially cause any issues? BEGIN EXPIRES <ifmodule mod_expires.c="">ExpiresActive On
Intermediate & Advanced SEO | | kimmiedawn
ExpiresDefault "access plus 10 days"
ExpiresByType text/css "access plus 1 week"
ExpiresByType text/plain "access plus 1 month"
ExpiresByType image/gif "access plus 1 month"
ExpiresByType image/png "access plus 1 month"
ExpiresByType image/jpeg "access plus 1 month"
ExpiresByType application/x-javascript "access plus 1 month"
ExpiresByType application/javascript "access plus 1 week"
ExpiresByType application/x-icon "access plus 1 year"</ifmodule> END EXPIRES (Edit) I'd like to add that there is a Wordpress blog on the site too at www.example.com/blog with the following code in it's .htaccess: BEGIN WordPress <ifmodule mod_rewrite.c="">RewriteEngine On
RewriteBase /blog/
RewriteRule ^index.php$ - [L]
RewriteCond %{REQUEST_FILENAME} !-f
RewriteCond %{REQUEST_FILENAME} !-d
RewriteRule . /blog/index.php [L]</ifmodule> END WordPress Thanks0 -

301 - should I redirect entire domain or page for page?
Hi, We recently enabled a 301 on our domain from our old website to our new website. On the advice of fellow mozzer's we copied the old site exactly to the new domain, then did the 301 so that the sites are identical. Question is, should we be doing the 301 as a whole domain redirect, i.e. www.oldsite.com is now > www.newsite.com, or individually setting each page, i.e. www.oldsite.com/page1 is now www.newsite.com/page1 etc for each page in our site? Remembering that both old and new sites (for now) are identical copies. Also we set the 301 about 5 days ago and have verified its working but haven't seen a single change in rank either from the old site or new - is this because Google hasn't likely re-indexed yet? Thanks, Anthony
Intermediate & Advanced SEO | | Grenadi0