Why are Google SERP Sitelinks "Not Working?"
-
Hi,
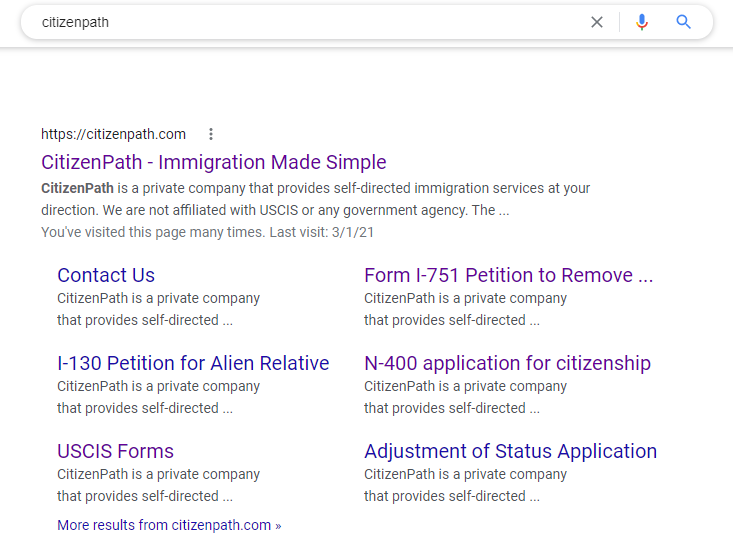
I'm hoping someone can provide some insight. I Google searched "citizenpath" recently and found that all of our our sitelinks have identical text. The text seems to come from the site footer. It isn't using the meta descriptions (we definitely have) or even a Google-dictated snippet from the page. I understand we don't have "control" of this. It's also worth mentioning that if you search a specific page like "contact us citizenpath" you'll get a more appropriate excerpt.
Can you help us understand what is happening? This isn't helpful for Google users or CitizenPath. Did the Google algorithm go awry or is there a technical error on our site? We use up-to-date versions of Wordpress and Yoast SEO. Thanks!
-
@123russ let me know how it goes.
PS: I'd appreciate upvote if you find my suggestions helpful. -
@123russ let me know how it goes.
PS: I'd appreciate upvote if you find my suggestions helpful. -
@terentyev Thank you for taking the time to review this. I'll ask our team to review your suggestions.
-
@123russ I checked your site, and it seems that there is an issue with embedded iframes you are using on your site.
Check out your document outline in W3 validator and tell your developer to fix fatal errors (in your case - multiple body tags).Another thing I would do is to add the texts that you are using in meta descriptions somewhere on the top of the page, behind the H1 title.
Got a burning SEO question?
Subscribe to Moz Pro to gain full access to Q&A, answer questions, and ask your own.
Browse Questions
Explore more categories
-
Moz Tools
Chat with the community about the Moz tools.
-
SEO Tactics
Discuss the SEO process with fellow marketers
-
Community
Discuss industry events, jobs, and news!
-
Digital Marketing
Chat about tactics outside of SEO
-
Research & Trends
Dive into research and trends in the search industry.
-
Support
Connect on product support and feature requests.
Related Questions
-

[Organization schema] Which Facebook page should be put in "sameAs" if our organization has separate Facebook pages for different countries?
We operate in several countries and have this kind of domain structure:
Technical SEO | | Telsenome
example.com/us
example.com/gb
example.com/au For our schemas we've planned to add an Organization schema on our top domain, and let all pages point to it. This introduces a problem and that is that we have a separate Facebook page for every country. Should we put one Facebook page in the "sameAs" array? Or all of our Facebook pages? Or should we skip it altogether? Only one Facebook page:
{
"@type": "Organization",
"@id": "https://example.com/org/#organization",
"name": "Org name",
"url": "https://example.com/org/",
"sameAs": [
"https://www.linkedin.com/company/xxx",
"https://www.facebook.com/xxx_us"
], All Facebook pages:
{
"@type": "Organization",
"@id": "https://example.com/org/#organization",
"name": "Org name",
"url": "https://example.com/org/",
"sameAs": [
"https://www.linkedin.com/company/xxx",
"https://www.facebook.com/xxx_us"
"https://www.facebook.com/xxx_gb"
"https://www.facebook.com/xxx_au"
], Bonus question: This reasoning springs from the thought that we only should have one Organization schema? Or can we have a multiple sub organizations?0 -

Quick Fix to "Duplicate page without canonical tag"?
When we pull up Google Search Console, in the Index Coverage section, under the category of Excluded, there is a sub-category called ‘Duplicate page without canonical tag’. The majority of the 665 pages in that section are from a test environment. If we were to include in the robots.txt file, a wildcard to cover every URL that started with the particular root URL ("www.domain.com/host/"), could we eliminate the majority of these errors? That solution is not one of the 5 or 6 recommended solutions that the Google Search Console Help section text suggests. It seems like a simple effective solution. Are we missing something?
Technical SEO | | CREW-MARKETING1 -

How can I Style Long "List Posts" in Wordpress?
Hi All, I have been working on a list-post which spans over 100 items. Each item on the list has a quick blurb to explain it, an image and a few resource links. I am trying to find an attractive way to present this long list post in Wordpress. I have seen several sites with long list posts however; they place their items one on top of the other which yields a VERY long page and the end user has to do a lot of scrolling. Others turn their lists into slideshows, but I have no data on how slides perform against 10-mile-long-lists which load in 1 page. I would like to do something similar to what List25.com does as they present about 5-10 items per page and they seem to have pagination. The pagination part I understand however; is there a shortcode plugin to format lists in an attractive way just like list25?
Technical SEO | | IvanC0 -

Website Migration - Very Technical Google "Index" Question
This is my understanding of how Google's search works, and I am unsure about one thing in specifc: Google continuously crawls websites and stores each page it finds (let's call it "page directory") Google's "page directory" is a cache so it isn't the "live" version of the page Google has separate storage called "the index" which contains all the keywords searched. These keywords in "the index" point to the pages in the "page directory" that contain the same keywords. When someone searches a keyword, that keyword is accessed in the "index" and returns all relevant pages in the "page directory" These returned pages are given ranks based on the algorithm The one part I'm unsure of is how Google's "index" connects to the "page directory". I'm thinking each page has a url in the "page directory", and the entries in the "index" contain these urls. Since Google's "page directory" is a cache, would the urls be the same as the live website? For example if webpage is found at wwww.website.com/page1, would the "page directory" store this page under that url in Google's cache? The reason I ask is I am starting to work with a client who has a newly developed website. The old website domain and files were located on a GoDaddy account. The new websites files have completely changed location and are now hosted on a separate GoDaddy account, but the domain has remained in the same account. The client has setup domain forwarding/masking to access the files on the separate account. From what I've researched domain masking and SEO don't get along very well. Not only can you not link to specific pages, but if my above assumption is true wouldn't Google have a hard time crawling and storing each page in the cache?
Technical SEO | | reidsteven750 -

Link to Articles for news sites in Google SERPs
I'm trying to figure out why when I search for "international news" or "world news", for example, some sites in the SERPs have links to news articles, while others don't. For "international news", result of Fox News and New York Times have links to articles, while CNN (the top result), only have sitelinks. I would appreciate any theories on why this happens. Thanks.
Technical SEO | | seoFan210 -

Sitemaps and "noindex" pages
Experimenting a little bit to recover from Panda and added "noindex" tag for quite a few pages. Obviously now we need Google to re-crawl them ASAP and de-index. Should we leave these pages in sitemaps (with updated "lastmod") for that? Or just patiently wait? 🙂 What's the common/best way?
Technical SEO | | LocalLocal0 -

Same URL in "Duplicate Content" and "Blocked by robots.txt"?
How can the same URL show up in Seomoz Crawl Diagnostics "Most common errors and warnings" in both the "Duplicate Content"-list and the "Blocked by robots.txt"-list? Shouldnt the latter exclude it from the first list?
Technical SEO | | alsvik0 -

Google Sitelinks
We have an e-commerce site that has about 50k pageviews of our main shop page every week. However in our Google sitelinks we have one for 'Shop'. However, for the Shop sitelink Google is linking to a random URL that we have never & would never use as a URL and not to our Shop page. I can't work out why Google would pick up this random url as we have so many links etc to the main shop page. Why are they not linking to the right page? I have blocked that url in webmaster tools and done a redirect but I want to understand why it happened in the first place. It included 'swedish+fish' so it seems weirdly spammy?! Any thoughts would be really helpful (and I am only mildly techy). Many thanks
Technical SEO | | ahamill0