After more than 13 years, and tens of thousands of questions, Moz Q&A closed on 12th December 2024. Whilst we’re not completely removing the content - many posts will still be possible to view - we have locked both new posts and new replies. More details here.
Solved How to solve orphan pages on a job board
-
Working on a website that has a job board, and over 4000 active job ads. All of these ads are listed on a single "job board" page, and don’t obviously all load at the same time.
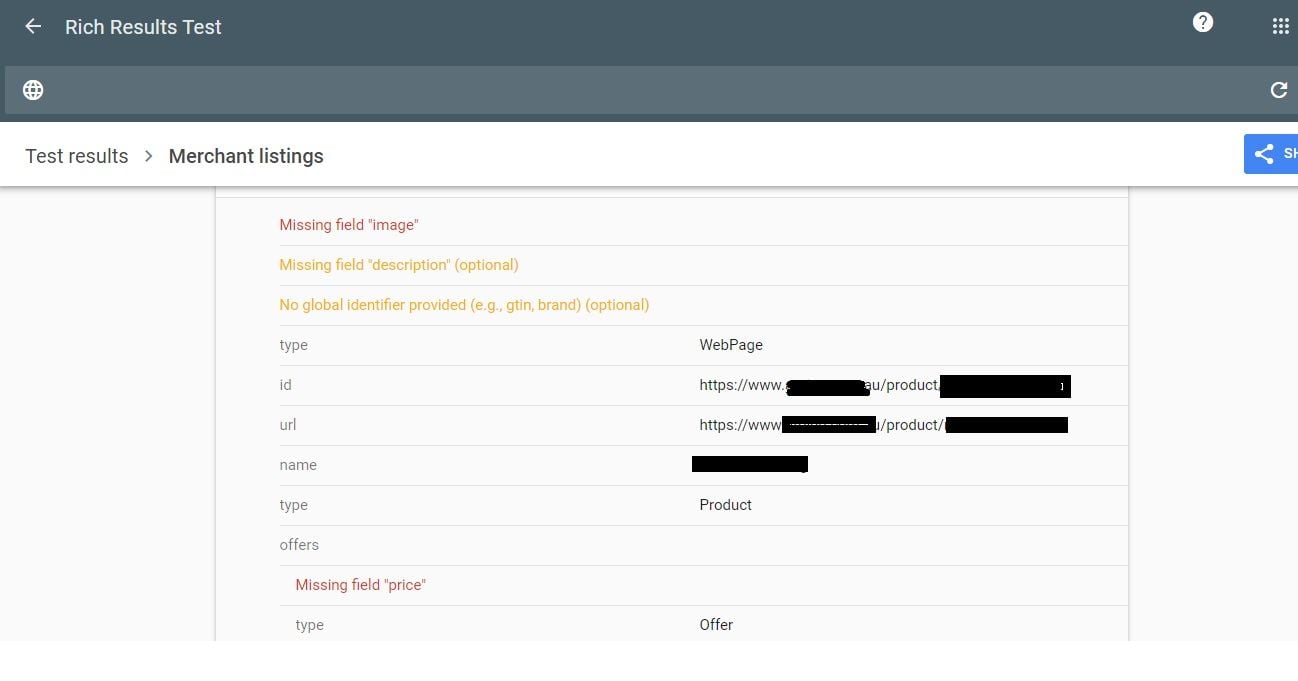
They are not linked to from anywhere else, so all tools are listing all of these job ad pages as orphans.
How much of a red flag are these orphan pages? Do sites like Indeed have this same issue? Their job ads are completely dynamic, how are these pages then indexed?
We use Google’s Search API to handle any expired jobs, so they are not the issue. It’s the active, but orphaned pages we are looking to solve. The site is hosted on WordPress.
What is the best way to solve this issue? Just create a job category page and link to each individual job ad from there? Any simpler and perhaps more obvious solutions? What does the website structure need to be like for the problem to be solved? Would appreciate any advice you can share!
-
@cyrus-shepard-0 Thanks so much for your input! The categorization option was what we were thinking about as well, but not sure if the client will be ready to invest the time. Will definitely suggest it to them.
Not majorly concerned about the jobs being found via Google search as individual posts, it's more about avoiding the orphans, as I'm sure they will be seen as a red flag.
Also, yes, the job posts are covered in a sitemap, you are correct.
-
@michael_m Seems like you have a number of options.
Can you categorize the jobs into more specific types (e.g. region, job type, etc.) and then add them to more category-specific "job board" pages? Even if you had duplication across job boards, seems like you'd get better crawl + indexation coverage. Anything to create a more clear crawling path to those pages. Even 20-50 job categories (or other sort/filter features) might provide benefit, and those category pages probably have a better chance of ranking on their own.
Cross-linking from similar/related jobs might also be a good option to explore. Much how we link to related questions here in the Q&A.
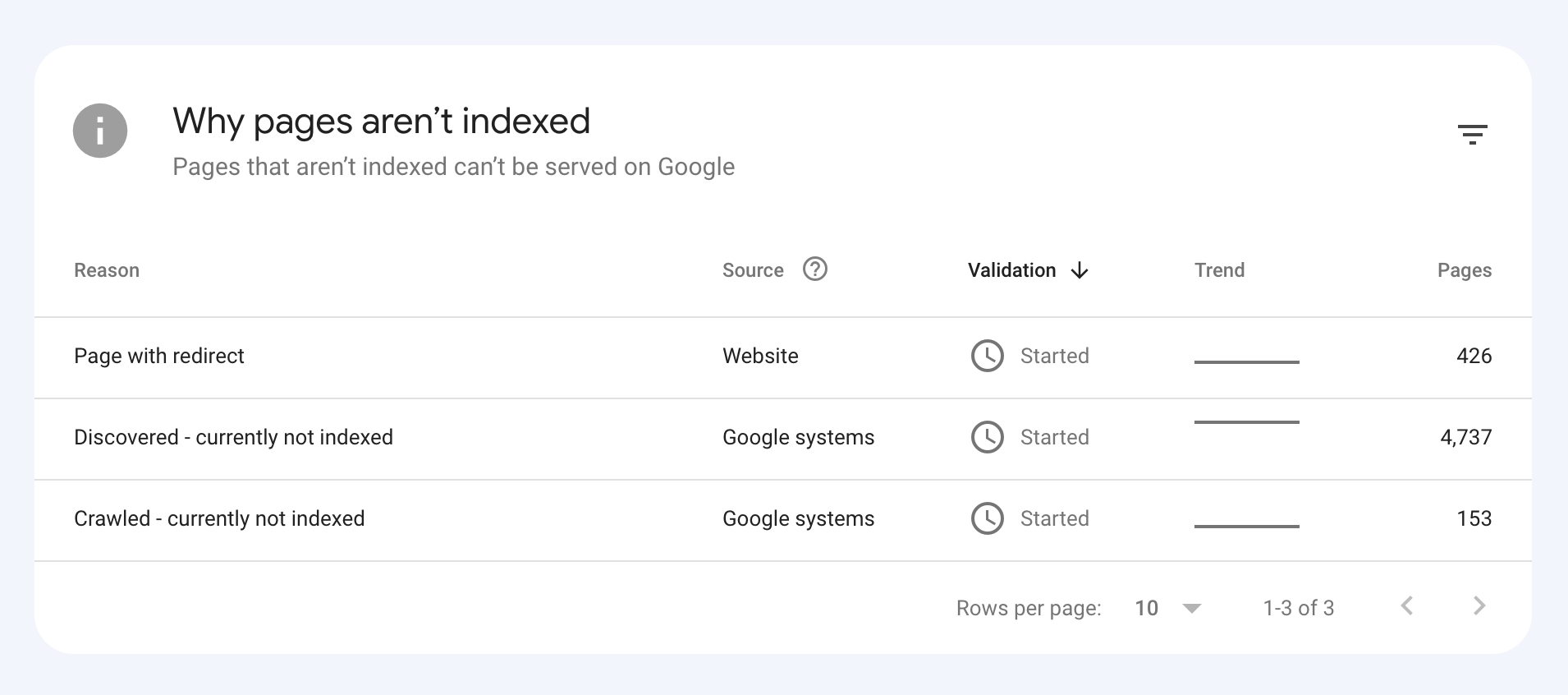
Orphaned pages aren't always a problem, as long as the pages are getting indexed and ranked. I imagine the search volume is pretty low for some of those jobs, but Google's sitemap indexation report is going to be your friend here.
Hope that helps!
Are the job postings covered in a sitemap? As SEO tools are finding them as orphaned, I assume they are discovering the pages via sitemaps.
Got a burning SEO question?
Subscribe to Moz Pro to gain full access to Q&A, answer questions, and ask your own.
Explore more categories
-
Chat with the community about the Moz tools.
-
Discuss the SEO process with fellow marketers
-
Discuss industry events, jobs, and news!
-
Chat about tactics outside of SEO
-
Dive into research and trends in the search industry.
-
Support
Connect on product support and feature requests.
-
-
 091.3k
091.3k
-
 084.1k
084.1k
-
 052.0k
052.0k
-
 062.5k
062.5k
-
 073.6k
073.6k
-
 053.5k
053.5k
-
 012.9k
012.9k
-
 1114.7k
1114.7k