Unsolved Strange "?offset" URL found with content crawl issues
-
I recently recieved a slew of content crawl issues via Moz for URL's that I have never seen before
For example:
Standard URL: https://skilldirector.com/news,
Newly identified URL: https://skilldirector.com/news?offset=1469542207800&category=Competency+Management).Does anyone know where the URL comes from and how to fix it?
-
@meghanpahinui thank you!
-
Hi there! Thanks so much for the post!
I took a look at the links/pages you provided and it seems these URLs are originating from the pagination on your category pages. For example, if I head to https://skilldirector.com/news/category/Competency+Management and then click "Older" at the bottom of the category page, the next page is an offset URL. I was also able to find the ?offset URL in the source code:
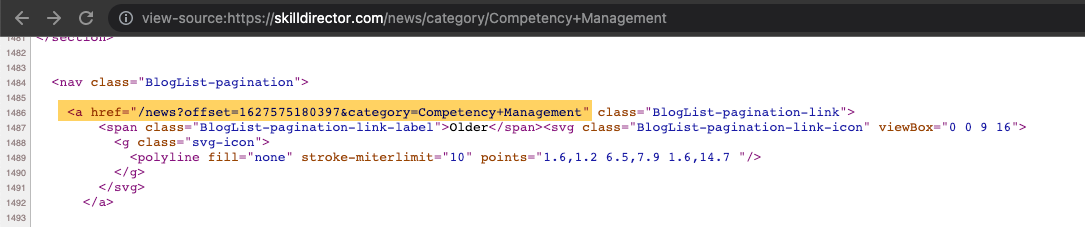
I hope this helps to point you in the right direction!
Got a burning SEO question?
Subscribe to Moz Pro to gain full access to Q&A, answer questions, and ask your own.
Browse Questions
Explore more categories
-
Moz Tools
Chat with the community about the Moz tools.
-
SEO Tactics
Discuss the SEO process with fellow marketers
-
Community
Discuss industry events, jobs, and news!
-
Digital Marketing
Chat about tactics outside of SEO
-
Research & Trends
Dive into research and trends in the search industry.
-
Support
Connect on product support and feature requests.
Related Questions
-

Unsolved URL dynamic structure issue for new global site where I will redirect multiple well-working sites.
Dear all, We are working on a new platform called [https://www.piktalent.com](link url), were basically we aim to redirect many smaller sites we have with quite a lot of SEO traffic related to internships. Our previous sites are some like www.spain-internship.com, www.europe-internship.com and other similars we have (around 9). Our idea is to smoothly redirect a bit by a bit many of the sites to this new platform which is a custom made site in python and node, much more scalable and willing to develop app, etc etc etc...to become a bigger platform. For the new site, we decided to create 3 areas for the main content: piktalent.com/opportunities (all the vacancies) , piktalent.com/internships and piktalent.com/jobs so we can categorize the different types of pages and things we have and under opportunities we have all the vacancies. The problem comes with the site when we generate the diferent static landings and dynamic searches. We have static landing pages generated like www.piktalent.com/internships/madrid but dynamically it also generates www.piktalent.com/opportunities?search=madrid. Also, most of the searches will generate that type of urls, not following the structure of Domain name / type of vacancy/ city / name of the vacancy following the dynamic search structure. I have been thinking 2 potential solutions for this, either applying canonicals, or adding the suffix in webmasters as non index.... but... What do you think is the right approach for this? I am worried about potential duplicate content and conflicts between static content dynamic one. My CTO insists that the dynamic has to be like that but.... I am not 100% sure. Someone can provide input on this? Is there a way to block the dynamic urls generated? Someone with a similar experience? Regards,
Technical SEO | | Jose_jimenez0 -

Unsolved URL Crawl Reports providing drastic differences: Is there something wrong?
A bit at a loss here. I ran a URL crawl report at the end of January on a website( https://www.welchforbes.com/ ). There were no major critical issues at the time. No updates were made on the website (that I'm aware of), but after running another crawl on March 14, the report was short about 90 pages on the site and suddenly had a ton of 403 errors. I ran a crawl again on March 15 to check if there was perhaps a discrepancy, and the report crawled even fewer pages and had completely different results again. Is there a reason the results are differing from report to report? Is there something about the reports that I'm not understanding or is there a serious issue within the website that needs to be addressed? Jan. 28 results:
Reporting & Analytics | | OliviaKantyka
Screen Shot 2022-03-16 at 3.00.52 PM.png March 14 results:
Screen Shot 2022-03-15 at 10.31.22 AM.png March 15 results:
Screen Shot 2022-03-15 at 4.06.42 PM.png0 -

Rogerbot crawls my site and causes error as it uses urls that don't exist
Whenever the rogerbot comes back to my site for a crawl it seems to want to crawl urls that dont exist and thus causes errors to be reported... Example:- The correct url is as follows: /vw-baywindow/cab_door_slide_door_tailgate_engine_lid_parts/cab_door_seals/genuine_vw_brazil_cab_door_rubber_68-79_10330/ But it seems to want to crawl the following: /vw-baywindow/cab_door_slide_door_tailgate_engine_lid_parts/cab_door_seals/genuine_vw_brazil_cab_door_rubber_68-79_10330/?id=10330 This format doesn't exist anywhere and never has so I have no idea where its getting this url format from The user agent details I get are as follows: IP ADDRESS: 107.22.107.114
Moz Pro | | spiralsites
USER AGENT: rogerbot/1.0 (http://moz.com/help/pro/what-is-rogerbot-, rogerbot-crawler+pr1-crawler-17@moz.com)0 -

Rel="canonical" tag is implemented in my product pages, but still getting canoncal error for products in Moz. What is the problem? me or MOZ?
I have included the rel="canonical" tag in all my product pages, but still getting canonical error in MOZ reports for more than 6 month ! I would like to know if my code is wrong or the MOZ report system is not working properly. Here is an example of my canonical code in line 84 rel="canonical" href="http://www.doornmore.com/slab-single-door-80-fiberglass-courtlandt-1-panel-arch-lite-glass.html" /> Thanks Shayann
Moz Pro | | Shayann0 -

Campaign Domain "change" (www. vs no www.)
Hello, I'm tracking a domain (with www.thespin.be) since months. Last week we changed things related to domain & server and now SEOmoz has 0 pages crawled. I think that's because now my main domain is without www. (thespin.be). How can I modify my campaign to reflect this "change" (that's not really a new domain..) to avoid losing all my campaign history ? Also, on Google Webmaster Tools it's like I have 2 different sites (one with www. and another without), although I've defined my favorite domain (without www.) months ago.. Google won't update its index. And I have this problem on several other sites.. Thank you very much for giving me a feedback. Regards Jean-Louis
Moz Pro | | JeanlouisSEO1 -

Crawled pages are missing and showing just 1 page crawled
One of my campaign has got around 8500 pages crawled(seomoz) and reports are shown, but suddenly it is showing 1 page crawled. Why it is happened like this? How can i get back the previous reports?
Moz Pro | | Sulekha0 -

Why do I keep getting "more than one canonical URL tag" on-page factor when, in fact, there is always only one?
The following are pages that SEOMOZ says have "more than one canonical URL tag" but they all have only one. Can someone help me understand this?http://www.lasercenterny.com/Laser-Hair-Removal-Binghamton/tabid/1950/Default.aspxhttp://www.lasercenterny.com/Hair-Removal-Binghamton-NY/tabid/1949/Default.aspxhttp://www.lasercenterny.com/Hair-Removal-Binghamton/tabid/1948/Default.aspx
Moz Pro | | SmartWebPros0 -

How do I get the Page Authority of individual URLs in my exported (CSV) crawl reports?
I need to prioritize fixes somehow. It seems the best way to do this would be to filter my exported crawl report by the Page Authority of each URL with an error/issue. However, Page Authority doesn't seem to be included in the crawl report's CSV file. Am I missing something?
Moz Pro | | Twilio0