Unsolved Strange "?offset" URL found with content crawl issues
-
I recently recieved a slew of content crawl issues via Moz for URL's that I have never seen before
For example:
Standard URL: https://skilldirector.com/news,
Newly identified URL: https://skilldirector.com/news?offset=1469542207800&category=Competency+Management).Does anyone know where the URL comes from and how to fix it?
-
@meghanpahinui thank you!
-
Hi there! Thanks so much for the post!
I took a look at the links/pages you provided and it seems these URLs are originating from the pagination on your category pages. For example, if I head to https://skilldirector.com/news/category/Competency+Management and then click "Older" at the bottom of the category page, the next page is an offset URL. I was also able to find the ?offset URL in the source code:
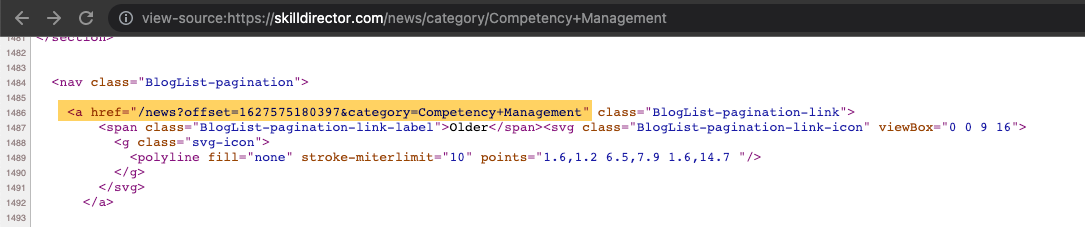
I hope this helps to point you in the right direction!
Got a burning SEO question?
Subscribe to Moz Pro to gain full access to Q&A, answer questions, and ask your own.
Browse Questions
Explore more categories
-
Moz Tools
Chat with the community about the Moz tools.
-
SEO Tactics
Discuss the SEO process with fellow marketers
-
Community
Discuss industry events, jobs, and news!
-
Digital Marketing
Chat about tactics outside of SEO
-
Research & Trends
Dive into research and trends in the search industry.
-
Support
Connect on product support and feature requests.
Related Questions
-

Unsolved Crawling error emails
Recently we start having random error messages about crawling issue:
Product Support | | DTashjian
2024-08-30 edweek:Ok
2024-08-29 marketbrief:Err. advertise: Err, edweek:Err, topschooljobs:Ok
2024-08-23 edweek:Ok
2024-08-22 marketbrief:Err. advertise: Err, edweek:Err
2024-08-21 topschooljobs:Ok, edweek:Ok
2024-08-15 marketbrief:Ok. advertise:OK
2024-08-13 edweek:Ok
2024-08-12 marketbrief:Ok
2024-08-08 marketbrief:Ok, advertise:Ok
2024-08-03 edweek:Ok, topschooljobs:Ok
All for 2024-07 - are Ok Yesterday I set 2 more crawls for the same sites (edweek and marketbrief) and I get a morning email about original edweek site is ok (still have some problem but crawl occurs and all is fine) but for test crawl for the same site "EW Test" I just got error email.
Also I suppressed ALL email communications and frankly surprised by this email. Can you please check what is wrong with a crawler or stat collection or I don't know who produced the issues.0 -

Unsolved Rogerbot blocked by cloudflare and not display full user agent string.
Hi, We're trying to get MOZ to crawl our site, but when we Create Your Campaign we get the error:
Moz Pro | | BB_NPG
Ooops. Our crawlers are unable to access that URL - please check to make sure it is correct. If the issue persists, check out this article for further help. robot.txt is fine and we actually see cloudflare is blocking it with block fight mode. We've added in some rules to allow rogerbot but these seem to be getting ignored. If we use a robot.txt test tool (https://technicalseo.com/tools/robots-txt/) with rogerbot as the user agent this get through fine and we can see our rule has allowed it. When viewing the cloudflare activity log (attached) it seems the Create Your Campaign is trying to crawl the site with the user agent as simply set as rogerbot 1.2 but the robot.txt testing tool uses the full user agent string rogerbot/1.0 (http://moz.com/help/pro/what-is-rogerbot-, rogerbot-crawler+shiny@moz.com) albeit it's version 1.0. So seems as if cloudflare doesn't like the simple user agent. So is it correct the when MOZ is trying to crawl the site it uses the simple string of just rogerbot 1.2 now ? Thanks
Ben Cloudflare activity log, showing differences in user agent strings
2022-07-01_13-05-59.png0 -

How get rid of 403 crawl error?
My wordpress website has 162 crawl 403 errors. Based on what I read it means that the server is denying crawlers to access the pages. The pages itself will load so guessing it's just an issue with crawlers only. How do I go about fixing this issue?
On-Page Optimization | | emrekeserr30 -

Unsolved Halkdiki Properties
Hello,
Moz Pro | | TheoVavdinoudis
I have a question about Site Crawl: Content Issues segment. I have an e-shop and moz showing me problem because my urls are too similar and my H1s are the same
<title>Halkdiki Properties
https://halkidikiproperties.com/en/properties?property_category=1com&property_subcategory=&price_min_range=&price_max_range=&municipality=&area=&sea_distance=&bedroom=&hotel_bedroom=&bathroom=&place=properties&pool=&sq_min=&sq_max=&year_default=&fetures=&sort=1&length=12&ids= <title>Halkdiki Properties
https://halkidikiproperties.com/en/properties?property_category=2&property_subcategory=&price_min_range=0&price_max_range=0&municipality=&area=&sea_distance=&bedroom=0&hotel_bedroom=0&bathroom=0&place=properties&pool=0&sq_min=&sq_max=&year_default=&fetures=&sort=1&length=12&ids= Can someone help, is a big problem or I ignore it?? thank you0 -

How to sift "site search" data from Google Analytics for trends
I apologize in advance if this has been asked a million times but I'm just not able to find anything on it for some reason. Probably the words "site" and "search" come up a lot in this area... Anyhow, my question: How do I find trends in "site search" data from Google Analytics? I set up "site search" a long time ago. I have thousands and thousands of searches people have made on my site logged and squirreled away. The plan was to review them on a weekly basis, find the trends and start writing content to address interests people seem to be having but not finding on our site. Sounded great at the time. The problem I have, of course, is that among my 10,000 searches (many shown in Google Analytics as "no-results:cats and dogs", etc), there are slight differences that make it difficult to total up search trends. Let's say the list is like this: Term | Search Count Cats | 500
Moz Pro | | rtkl
Dogs | 500
Cat | 250
Dog | 250
Cat food | 5
Dog food | 5
Birds | 1
Bird | 1
Cats are great | 1
Cats are really great | 1
Dogs are great | 1
I like birds | 1
Seriously, I like Cats | 1
Turtles | 1 ... 10,000 more entries, every single one only 1 search per term. OK, so it looks like people like Cats and Dogs a lot, but also Birds and Turtles. But maybe there are snake searches. Maybe there are "cat pajamas" searches and variations on all of the above. Who knows what else is really trending in there??? The review of this data is MIND-NUMBING. Especially when you get into plurality and misspellings, this rabbit hole has no bottom. Is there a tool people in the SEO jam use to take a big ole CSV dump and have it magically sorted by at least potential trends? I mean, there's gotta be, right? And I'm silly for not already knowing what it is.0 -

Duplicate content error?
I am getting a duplicate content error for the following pages: http://www.bluelinkerp.com/products/accounting/index.asp http://www.bluelinkerp.com/products/accounting/ But, of course, the 2nd link is just an automatic redirect to the index file, is it not? Why is it thinking it is a different URL? See image. NJfxA.png
Moz Pro | | BlueLinkERP0 -

I've got quite a few "Duplicate Page Title" Errors in my Crawl Diagnostics for my Wordpress Blog
Title says it all, is this an issue? The pages seem to be set up properly with Rel=Canonical so should i just ignore the duplicate page title erros in my Crawl Diagnostics dashboard? Thanks
Moz Pro | | SheffieldMarketing0 -

SEOmoz bot and "noindex"
As a recent newbie to SEOmoz, I've been implementing some suggestions and doing a general tidy up. I removed URL's from our robots txt, and rolled out instead the noindex meta tag to pages we don't want indexed. But surprised to see issues that are now flagged from the last crawl by the moz bot from pages that have this meta tag? Does the SEOmoz bot not ignore this tag? Just want to make sure I've implemented it correctly, so the google bot does ignore it. Meta tag syntax is and is placed below the title tag. cheers Steve
Moz Pro | | sjr4x40