After more than 13 years, and tens of thousands of questions, Moz Q&A closed on 12th December 2024. Whilst we’re not completely removing the content - many posts will still be possible to view - we have locked both new posts and new replies. More details here.
Page Indexing without content
-
Hello.
I have a problem of page indexing without content. I have website in 3 different languages and 2 of the pages are indexing just fine, but one language page (the most important one) is indexing without content. When searching using site: page comes up, but when searching unique keywords for which I should rank 100% nothing comes up.
This page was indexing just fine and the problem arose couple of days ago after google update finished. Looking further, the problem is language related and every page in the given language that is newly indexed has this problem, while pages that were last crawled around one week ago are just fine.
Has anyone ran into this type of problem?
-
I've encountered a similar indexing issue on my website, https://sunasusa.com/. To resolve it, ensure that the language markup and content accessibility on the affected pages are correct. Review any recent changes and the quality of your content. Utilize Google Search Console for insights, or consider reaching out to Google support for assistance.
-
To remove hacked URLs in bulk from Google's index, clean up your website, secure it, and then use Google Search Console to request removal of the unwanted URLs. Additionally, submit a new sitemap containing only valid URLs to expedite re-indexing.
-
It seems that after a recent Google update, one language version of your website is experiencing indexing issues, while others remain unaffected. This could be due to factors like changes in algorithms or technical issues. To address this:
- Check h reflag tags and content quality.
- Review technical aspects like crawlability and indexing directives. Deck Services in Duluth GA
- Monitor Google Search Console for errors.
- Consider seeking expert assistance if needed.
-
@AtuliSulava Re: Website blog is hacked. Whats the best practice to remove bad urls
something similar problem also happened to me. many urls are indexed but they have no content in actual. My website(scaleme) was hacked and thousands of URLs with Japanese content were added to my site. These URLs are now indexed by Google. How can I remove them in bulk? (ScreenShoot attached)
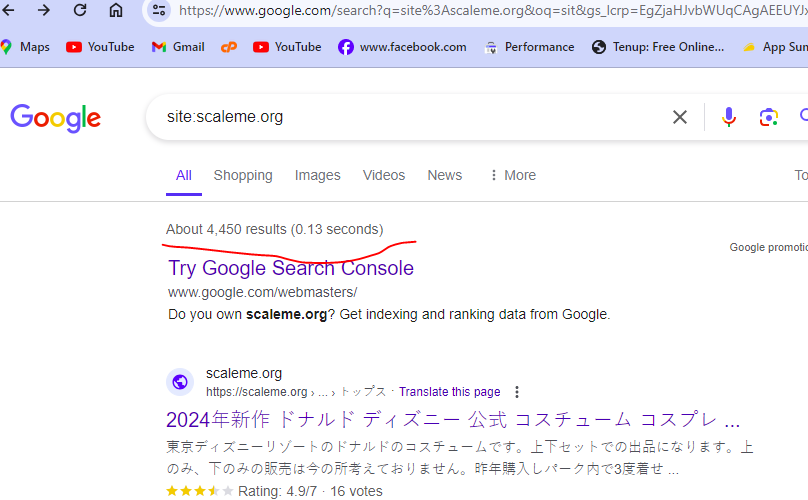
I am the owner of this website. thousands of Japanese-language URLs (more than 4400) were added to my site. i am aware with google url remover tool but adding one by one url and submitting for removing is not possible because there are large number of url indexed by google.
Is there a way to find these url , downlaod a list and remove these URLs in bulk? is Moz have any tool to solve this problem?
-
I've faced a similar indexing issue on my website https://mobilespackages.in/ myself. To resolve it, ensure correct language markup and content accessibility on the affected pages. Review recent changes and content quality. Utilize Google Search Console for insights or reach out to Google support.
-
@AtuliSulava It sounds like you're experiencing a frustrating issue with your website's indexing. I have faced this issue. Unfortunately, I have prevented my website from indexing in google by mistake. Here are some steps you can take to troubleshoot and potentially resolve the problem:
Check Robots.txt: Ensure that your site's robots.txt file is not blocking search engine bots from accessing the content on the affected pages.
Review Meta Tags: Check the <meta name="robots" content="noindex"> tag on the affected pages. If present, remove it to allow indexing.
Content Accessibility: Make sure that the content on the affected pages is accessible to search engine bots. Check for any JavaScript, CSS, or other elements that might be blocking access to the content.
Canonical Tags: Verify that the canonical tags on the affected pages are correctly pointing to the preferred version of the page.
Structured Data Markup: Ensure that your pages have correct structured data markup to help search engines understand the content better.
Fetch as Google: Use Google Search Console's "Fetch as Google" tool to see how Googlebot sees your page and if there are any issues with rendering or accessing the content.
Monitor Google Search Console: Keep an eye on Google Search Console for any messages or issues related to indexing and crawlability of your site.
Wait for Re-crawl: Sometimes, Google's indexing issues resolve themselves over time as the search engine re-crawls and re-indexes your site. If the problem persists, consider requesting a re-crawl through Google Search Console.
If the issue continues, it might be beneficial to seek help from a professional SEO consultant who can perform a detailed analysis of your website and provide specific recommendations tailored to your situation. -
@AtuliSulava Perhaps indexing of blank pages is prohibited on this site, look for more information on how to check the ban on indexing in which site files...
Got a burning SEO question?
Subscribe to Moz Pro to gain full access to Q&A, answer questions, and ask your own.
Explore more categories
-
Chat with the community about the Moz tools.
-
Discuss the SEO process with fellow marketers
-
Discuss industry events, jobs, and news!
-
Chat about tactics outside of SEO
-
Dive into research and trends in the search industry.
-
Support
Connect on product support and feature requests.
-
-
 0171.3k
0171.3k
-
 04532
04532
-
 06657
06657
-
 4263.9k
4263.9k
-
0213.4k
-
 041.6k
041.6k
-
 055.5k
055.5k
-
 11320.7k
11320.7k