Moz Q&A is closed.
After more than 13 years, and tens of thousands of questions, Moz Q&A closed on 12th December 2024. Whilst we’re not completely removing the content - many posts will still be possible to view - we have locked both new posts and new replies. More details here.
Should I "no-index" two exact pages on Google results?
-
Hello everyone,
I recently started a new wordpress website and created a static homepage.
I noticed that on Google search results, there are two different URLs landing on same content page.
I've attached an image to explain what I saw.
Should I "no-index" the page url?
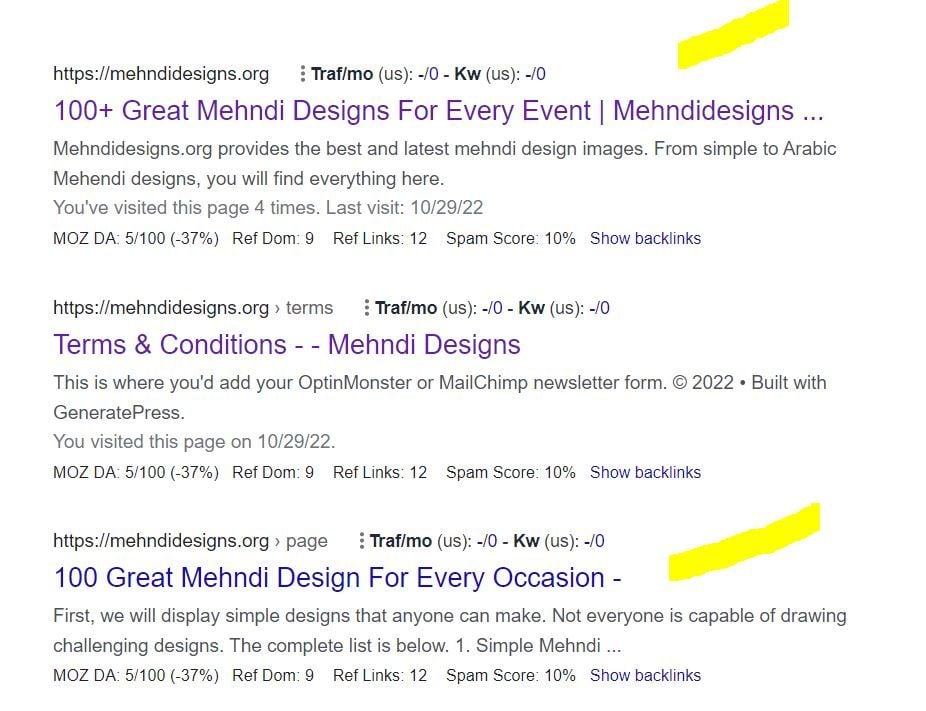
In this picture, the first result is the homepage and I try to rank for that page. The last result is landing on same content with different URL.
So, should I no-index last result as shown in image?
-
In any SEO plugin, you can go to edit the secondary article and in canonical URL you put the link to the home page.
-
@amanda5964 You can use canonical meta tag to tell google that those are the exact same pages. Google will index one of them which google choose best for the SERP.
-
Hi @amanda5964 actually could I ask if there is a reason for having these identical pages? You might want to consider simply combining the pages - i.e. deleting your sub page and redirecting to home if the content is identical.
-
I would not no-index. Typically it is more effective to use a canonical link from the secondary content to the main page you want the traffic directed to.
Got a burning SEO question?
Subscribe to Moz Pro to gain full access to Q&A, answer questions, and ask your own.
Browse Questions
Explore more categories
-
Moz Tools
Chat with the community about the Moz tools.
-
SEO Tactics
Discuss the SEO process with fellow marketers
-
Community
Discuss industry events, jobs, and news!
-
Digital Marketing
Chat about tactics outside of SEO
-
Research & Trends
Dive into research and trends in the search industry.
-
Support
Connect on product support and feature requests.
Related Questions
-

Page Indexing without content
Hello. I have a problem of page indexing without content. I have website in 3 different languages and 2 of the pages are indexing just fine, but one language page (the most important one) is indexing without content. When searching using site: page comes up, but when searching unique keywords for which I should rank 100% nothing comes up. This page was indexing just fine and the problem arose couple of days ago after google update finished. Looking further, the problem is language related and every page in the given language that is newly indexed has this problem, while pages that were last crawled around one week ago are just fine. Has anyone ran into this type of problem?
Technical SEO | | AtuliSulava1 -

Who is correct - please help!
I have a website with a lot of product pages - often thousands of pages. As each of these pages is for a specific lease car they are often only fractionally different from other pages. The urls are too long, the H1 is often too long and the Title is often too long for "SEO best practice". And they do create duplication issues according to MOZ. Some people tell me to change them to noindex/nofollow whilst others tell me to leave them as they are as best not to hide from google crawler. Any advice will be gratefully received. Thanks for listening.
Technical SEO | | jlhitch0 -

Shopify SEO - Double Filter Pages
Hi Experts, Single filter page: /collections/dining-chairs/black
Technical SEO | | williamhuynh
-- currently, canonical the same: /collections/dining-chairs/black
-- currently, index, follow Double filter page: /collections/dining-chairs/black+fabric
-- currently, canonical the same: /collections/dining-chairs/black+fabric
-- currently, noindex, follow My question is about double filter page above:
if noindexing is the better option OR should I change the canonical to /collections/dining-chairs/black Thank you0 -

To hyphenate or not to hyphenate?
Quick question: does Google differentiate between terms that correctly include a hyphen (such as "royalty-free") and those that are incorrect ("royalty free")? I ask because the correct term "royalty-free"(with a hyphen) receives far less monthly traffic for the same term without the hyphen (according to Moz): Term | Estimated traffic
On-Page Optimization | | JCN-SBWD
"royalty free music" | 11.5-30.3K
"royalty-free music" | 501-850 If Moz views the terms separately then I'd guess that Google does too, in which case the best thing to do for SEO (and increased site traffic) would be to wrongly use "royalty free" without the hyphen. Is that correct?0 -

Indexed, but not shown in search result
Hi all We face this problem for www.residentiebosrand.be, which is well programmed, added to Google Search Console and indexed. Web pages are shown in Google for site:www.residentiebosrand.be. Website has been online for 7 weeks, but still no search results. Could you guys look at the update below? Thanks!
Technical SEO | | conversal0 -

CDN Being Crawled and Indexed by Google
I'm doing a SEO site audit, and I've discovered that the site uses a Content Delivery Network (CDN) that's being crawled and indexed by Google. There are two sub-domains from the CDN that are being crawled and indexed. A small number of organic search visitors have come through these two sub domains. So the CDN based content is out-ranking the root domain, in a small number of cases. It's a huge duplicate content issue (tens of thousands of URLs being crawled) - what's the best way to prevent the crawling and indexing of a CDN like this? Exclude via robots.txt? Additionally, the use of relative canonical tags (instead of absolute) appear to be contributing to this problem as well. As I understand it, these canonical tags are telling the SEs that each sub domain is the "home" of the content/URL. Thanks! Scott
Technical SEO | | Scott-Thomas0 -

Should we use "and" or "&"?
Our client has an ampersand in their brand name. The logo has "&", their url is spelled out. I'm trying to get them to standardize the use of the name for directories/listings. Should we use "and" or "&"?
Technical SEO | | vernonmack0 -

301 for "index.php" in Web.config?
Hi there, I'm trying to create a 301 redirect for the file "index.php" but I keep getting a "fail to redirect" message in Firefox whenever I insert it into the Web.config file. <location path="index.php"></location> Is there anyway around this? Thanks for any help According to Open Site Explorer, there are about 500 links to my index file but it only has a 302 status so will not be passing link juice.
Technical SEO | | tdsnet0