Do I need robots.txt and meta robots?
-
If I can manage to tell crawlers what I do and don't want them to crawl for my whole site via my robots.txt file, do I still need meta robots instructions?
-
Older information, but mostly still relevant:
-
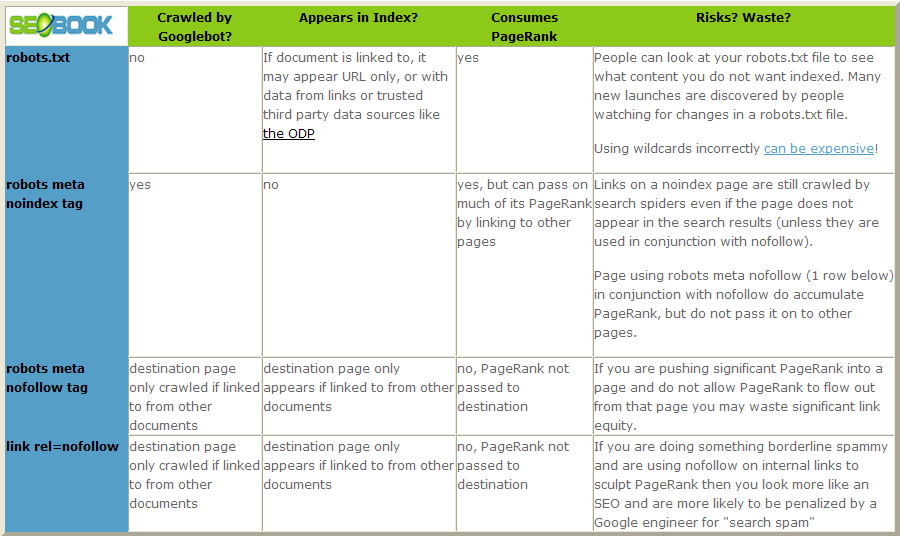
Although robots.txt and meta robots appear to do similar things, they both serve different functions.
Block with Robots.txt - This tells the engines to not crawl the given URL but tells them that they may keep the page in the index and display it in in results.
Block with Meta NoIndex - This tells engines they can visit but they are not allowed to display the URL in results. (this is a suggestion only - Google may still choose to show the URL)
Source: http://www.seomoz.org/learn-seo/robotstxt
The disadvantage of robots.txt is that it blocks Google from crawling the page, meaning no link juice can flow through the page, and if Google discovers the URL through other means (external links) it may show the URL anyway in search results, usually without a meta description.
The advantage of robots.txt is it can improve crawl efficiency - useful if you find Google crawling a bunch of unnecessary pages and eating up your crawl allowance.
Most of the time, I only use robots.txt to solve problems that I can't solve at the page level. I usually prefer to keep pages out of the index using a meta NOINDEX, FOLLOW tag.
-
If you want the stub listing removed as well, this is quite straight forward once you have it blocked in Robots. Instructions here: http://support.google.com/webmasters/bin/answer.py?hl=en&answer=1663419
Just checking though: If the content you are trying to remove is something private that should be hidden (as opposed to just low value stuff that you don't want cluttering the SERPS) then this isn't the right way to go about it. If that is the case reply back.
-
Hello Mat,
As far as I know if I blocked a url using robots.txt.For that page I will get only url in serps but i want to remove url from serps also.How to do that?
-
In short, no. You only need to include the instruction in one or the other. Most people find that the robots.txt file is the preferred solution because it will only take a few lines to specify which parts of a well structured site should and should not be crawled.
-
What do you mean by meta robots instructions? Are you referring to the meta tags that go on each individual page? In that case, no, you don't necessarily need them. Robots assume a page should be crawled unless told otherwise. I'd still do it for pages that you don't want indexed and/or followed because a lot of times, robots, especially Google, seem to ignore these directives.
{kind=link}
Got a burning SEO question?
Subscribe to Moz Pro to gain full access to Q&A, answer questions, and ask your own.
Browse Questions
Explore more categories
-
Moz Tools
Chat with the community about the Moz tools.
-
SEO Tactics
Discuss the SEO process with fellow marketers
-
Community
Discuss industry events, jobs, and news!
-
Digital Marketing
Chat about tactics outside of SEO
-
Research & Trends
Dive into research and trends in the search industry.
-
Support
Connect on product support and feature requests.
Related Questions
-

Bloking pages in roborts.txt that are under a redirected subdomain
Hi Everyone, I have a lot of Marketo landing pages that I don't want to show in SERP. Adding the noindex meta tag for each page will be too much, I have thousands of pages. Blocking it in roborts.txt could have been an option, BUT, the subdomain homepage is redirected to my main domain (with a 302) so I may confuse search engines ( should they follow the redirect or should they block) marketo.mydomain.com is redirected to www.mydomain.com disallow: / (I think this will be confusing with the redirect) I don't have folders, all pages are under the subdomain, so I can't block folders in Robots.txt also Would anyone had this scenario or any suggestions? I appreciate your thoughts here. Thank you Rachel
Technical SEO | | RaquelSaiz0 -

HTTP Status showing up in opensiteexplorer top pages as blocked by robot.txt file
I am trying to find an answer to this question it has alot of url on this page with no data when i go into the data source and search for noindex or robot.txt but the site is visible in the search engines ?
Technical SEO | | ReSEOlve0 -

A good META title for a front page....
Hi, We recently asked for some pointers to use on our site bit.ly/4Cogch as one of our SEOmoz private questions. One of the points that was picked up was that the title of the homepage looked quite spammy: Ink Cartridges | Toner Cartridges | Cheap Cartridges | Inkjet Ink | Laser Toner I completely see this however I've checked out our competition and no one seems to be doing things any better and the SEOmoz On Page SEO tool seems to like it so I'm not sure what changes to make. Does anybody have any inspiration that I could possibly use? It was suggested that Google is quite brand focused and so I should integrate the company name but how else would you change things, bearing in mind the ink and toner market that we're focusing on? Thanks for your help! Chris
Technical SEO | | ChrisHolgate0 -

I accidentally blocked Google with Robots.txt. What next?
Last week I uploaded my site and forgot to remove the robots.txt file with this text: User-agent: * Disallow: / I dropped from page 11 on my main keywords to past page 50. I caught it 2-3 days later and have now fixed it. I re-imported my site map with Webmaster Tools and I also did a Fetch as Google through Webmaster Tools. I tweeted out my URL to hopefully get Google to crawl it faster too. Webmaster Tools no longer says that the site is experiencing outages, but when I look at my blocked URLs it still says 249 are blocked. That's actually gone up since I made the fix. In the Google search results, it still no longer has my page title and the description still says "A description for this result is not available because of this site's robots.txt – learn more." How will this affect me long-term? When will I recover my rankings? Is there anything else I can do? Thanks for your input! www.decalsforthewall.com
Technical SEO | | Webmaster1230 -

How to allow one directory in robots.txt
Hello, is there a way to allow a certain child directory in robots.txt but keep all others blocked? For instance, we've got external links pointing to /user/password/, but we're blocking everything under /user/. And there are too many /user/somethings/ to just block every one BUT /user/password/. I hope that makes sense... Thanks!
Technical SEO | | poolguy0 -

Need specifics about mod_proxy for blog domain and 301s
I am getting the IT staff to move our blog from "blog." to "/blog" using mod_proxy for apache, but I had a couple of questions about this I was hoping someone here might be able to help with. Is it correct that just setting up mod_proxy will make the blog available at both URLs? the "blog." subdomain and the "/blog" folder? If so, what is the best way to 301 redirect all traffic from "blog." to "/blog"? I assume this could be handled with a blanket 301 style rewrite, but I wanted to get some other opinions before getting with my IT guys to do it. I am technical enough to talk about this, but not do it myself, so experienced opinions are appreciated. Thanks!
Technical SEO | | SL_SEM0 -

Robots.txt question
What is this robots.txt telling the search engines? User-agent: * Disallow: /stats/
Technical SEO | | DenverKelly0 -

Search engines have been blocked by robots.txt., how do I find and fix it?
My client site royaloakshomesfl.com is coming up in my dashboard as having Search engines have been blocked by robots.txt, only I have no idea where to find it and fix the problem. Please help! I do have access to webmaster tools and this site is a WP site, if that helps.
Technical SEO | | LeslieVS0