Do I need robots.txt and meta robots?
-
If I can manage to tell crawlers what I do and don't want them to crawl for my whole site via my robots.txt file, do I still need meta robots instructions?
-
Older information, but mostly still relevant:
-
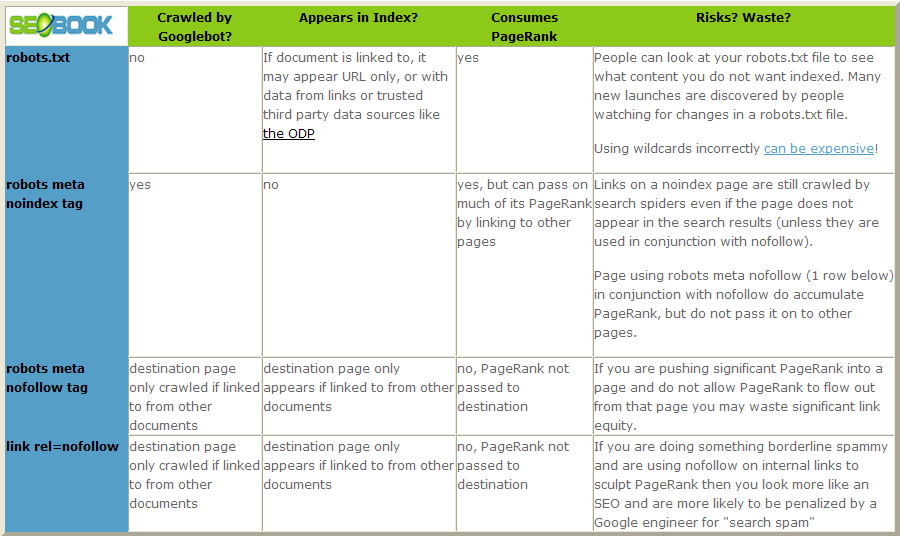
Although robots.txt and meta robots appear to do similar things, they both serve different functions.
Block with Robots.txt - This tells the engines to not crawl the given URL but tells them that they may keep the page in the index and display it in in results.
Block with Meta NoIndex - This tells engines they can visit but they are not allowed to display the URL in results. (this is a suggestion only - Google may still choose to show the URL)
Source: http://www.seomoz.org/learn-seo/robotstxt
The disadvantage of robots.txt is that it blocks Google from crawling the page, meaning no link juice can flow through the page, and if Google discovers the URL through other means (external links) it may show the URL anyway in search results, usually without a meta description.
The advantage of robots.txt is it can improve crawl efficiency - useful if you find Google crawling a bunch of unnecessary pages and eating up your crawl allowance.
Most of the time, I only use robots.txt to solve problems that I can't solve at the page level. I usually prefer to keep pages out of the index using a meta NOINDEX, FOLLOW tag.
-
If you want the stub listing removed as well, this is quite straight forward once you have it blocked in Robots. Instructions here: http://support.google.com/webmasters/bin/answer.py?hl=en&answer=1663419
Just checking though: If the content you are trying to remove is something private that should be hidden (as opposed to just low value stuff that you don't want cluttering the SERPS) then this isn't the right way to go about it. If that is the case reply back.
-
Hello Mat,
As far as I know if I blocked a url using robots.txt.For that page I will get only url in serps but i want to remove url from serps also.How to do that?
-
In short, no. You only need to include the instruction in one or the other. Most people find that the robots.txt file is the preferred solution because it will only take a few lines to specify which parts of a well structured site should and should not be crawled.
-
What do you mean by meta robots instructions? Are you referring to the meta tags that go on each individual page? In that case, no, you don't necessarily need them. Robots assume a page should be crawled unless told otherwise. I'd still do it for pages that you don't want indexed and/or followed because a lot of times, robots, especially Google, seem to ignore these directives.
{kind=link}
Got a burning SEO question?
Subscribe to Moz Pro to gain full access to Q&A, answer questions, and ask your own.
Browse Questions
Explore more categories
-
Moz Tools
Chat with the community about the Moz tools.
-
SEO Tactics
Discuss the SEO process with fellow marketers
-
Community
Discuss industry events, jobs, and news!
-
Digital Marketing
Chat about tactics outside of SEO
-
Research & Trends
Dive into research and trends in the search industry.
-
Support
Connect on product support and feature requests.
Related Questions
-

Is there a limit to how many URLs you can put in a robots.txt file?
We have a site that has way too many urls caused by our crawlable faceted navigation. We are trying to purge 90% of our urls from the indexes. We put no index tags on the url combinations that we do no want indexed anymore, but it is taking google way too long to find the no index tags. Meanwhile we are getting hit with excessive url warnings and have been it by Panda. Would it help speed the process of purging urls if we added the urls to the robots.txt file? Could this cause any issues for us? Could it have the opposite effect and block the crawler from finding the urls, but not purge them from the index? The list could be in excess of 100MM urls.
Technical SEO | | kcb81780 -

Meta Description
Working with a business that is having some real issues. They had some client information that was showing up in the meta description. Personal phone numbers for example. Our developers removed all the information from the pages in question two days ago, but we are still seeing the info in the meta description. Any idea how long this will take to be recrawled and fixed? Anything I can do to get recrawled sooner? Also, this is only happening in Bing/Yahoo and not in Google. Thanks for any help you can provide!
Technical SEO | | PGD20110 -

Need help with home page on site
Hello! Thanks for reading in advance! I've got a relatively old site (12 year old domain) that has experienced a drop in rankings specifically for our home page. Some of the key terms that I'd assume we would rank well for are: "expedite us passport" According to SEOMOZ, our on page optimization receives a C for the termr. also, the root domain and page have decent links, etc. However; looking at Google (logged out and in incognito mode in chrome), a page on our site http://www.passportsandvisas.com/passport/index.asp ranks well and our HOME page isn't listed in the top 50 or 100. THis is the case for a lot of keywords we used to rank well for. I would have thought our home page would have at least outranked an internal page. Any thoughts would be very, very helpful!
Technical SEO | | santiago230 -

Need advice on having customer stores running on my subdomain
We have an online store product and we're working on the SEO for our new domain (foo.com in this example.) Our customers have the ability to change the domain of their store but many of them will likely stick with the subdomains we give them (store1.foo.com) We could potentially have thousands of stores soon using our subdomain. Each of these stores will have a very small link at the bottom to our own domain but other than this, the content is completely user-generated and not under our control. Are there risks/problems associated with this type of strategy? If so, could we perhaps avoid them by using robots.txt to block entire site until they change to their own domain? TIA, Sean
Technical SEO | | schof0 -

Ajax #! URLs, Linking & Meta Refresh
Hi, We recently underwent a platform change and unfortunately our updated ecom site was coded using java script. The top navigation is uncrawlable, the pertinent product copy is undetectable and duplicated throughout the code, etc - it needs a lot of work to make it (even somewhat) seo-friendly. We're in the process of implementing ajax #! to our site and I've been tasked with creating a document of items that I will test to see if this solution will help our rankings, indexing, etc (on Google, I've read the issues w/ Bing). I have 2 questions: 1. Do I need to notify our content team who works on our linking strategy about the new urls? Would we use the #! url (for seo) or would we continue to use the clean url (without the #!) for inbound links? 2. When our site transferred over, we used meta refresh on all of the pages instead of 301s for some reason. Instead of going to a clean url, our meta refresh says this: . Would I update it to have the #! in the url? Should I try and clean up the meta refresh so it goes to an actual www. url and not this browsererrorview page? Or just push for the 301? I have read a ton of articles, including GWT docs, but I can't seem to find any solid information on these specific questions so any help I can get would be greatly appreciated. Thanks!
Technical SEO | | Improvements0 -

Link Volume - calculate what you need?
Hi everyone, an interesting question here. How do you determien what link volume you should try and get into your website? What analysis do you do to determine the number of links you feel is right to go into a back-link profiel every month? obviously there is no magic number but its an interesting question to know what others do. Obviously you don't want to build too many or too little. If you have been penalised for bad links in the past and are now back on track - how do you calculate the volume? Do you take links dropping out into consideration?
Technical SEO | | pauledwards0 -

Use of Robots.txt file on a job site
We are performing SEO on a large niche Job Board. My question revolves around the thought of no following all the actual job postings from their clients as they only last for 30 to 60 days. Anybody have any idea on the best way to handle this?
Technical SEO | | WebTalent0 -

Do sites really need a 404 page?
We have people posting broken links to our site is this looking us link juice as they link to 404 pages. We could redirect to the homepage or just render the home page content, in both cases we can still display a clear page not found message. Is this legal (white hat).
Technical SEO | | ed1234560