Do I need robots.txt and meta robots?
-
If I can manage to tell crawlers what I do and don't want them to crawl for my whole site via my robots.txt file, do I still need meta robots instructions?
-
Older information, but mostly still relevant:
-
Although robots.txt and meta robots appear to do similar things, they both serve different functions.
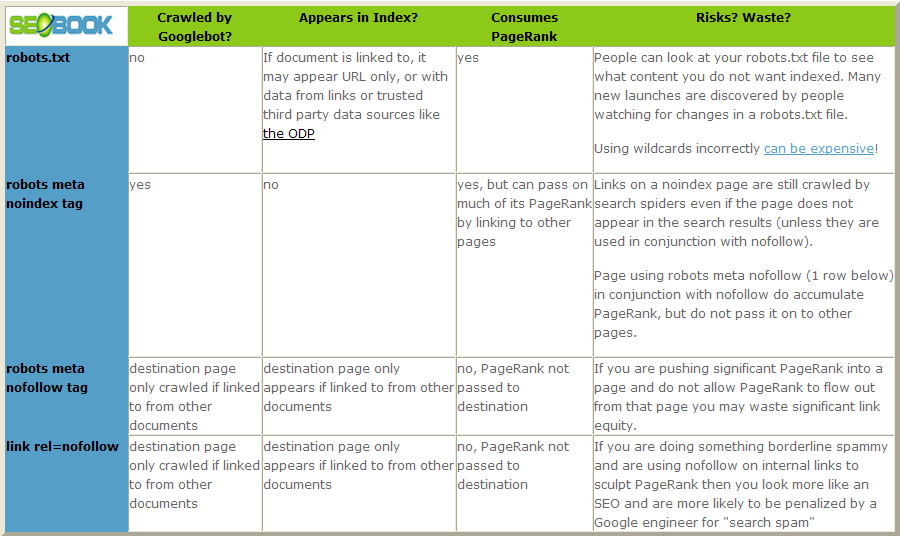
Block with Robots.txt - This tells the engines to not crawl the given URL but tells them that they may keep the page in the index and display it in in results.
Block with Meta NoIndex - This tells engines they can visit but they are not allowed to display the URL in results. (this is a suggestion only - Google may still choose to show the URL)
Source: http://www.seomoz.org/learn-seo/robotstxt
The disadvantage of robots.txt is that it blocks Google from crawling the page, meaning no link juice can flow through the page, and if Google discovers the URL through other means (external links) it may show the URL anyway in search results, usually without a meta description.
The advantage of robots.txt is it can improve crawl efficiency - useful if you find Google crawling a bunch of unnecessary pages and eating up your crawl allowance.
Most of the time, I only use robots.txt to solve problems that I can't solve at the page level. I usually prefer to keep pages out of the index using a meta NOINDEX, FOLLOW tag.
-
If you want the stub listing removed as well, this is quite straight forward once you have it blocked in Robots. Instructions here: http://support.google.com/webmasters/bin/answer.py?hl=en&answer=1663419
Just checking though: If the content you are trying to remove is something private that should be hidden (as opposed to just low value stuff that you don't want cluttering the SERPS) then this isn't the right way to go about it. If that is the case reply back.
-
Hello Mat,
As far as I know if I blocked a url using robots.txt.For that page I will get only url in serps but i want to remove url from serps also.How to do that?
-
In short, no. You only need to include the instruction in one or the other. Most people find that the robots.txt file is the preferred solution because it will only take a few lines to specify which parts of a well structured site should and should not be crawled.
-
What do you mean by meta robots instructions? Are you referring to the meta tags that go on each individual page? In that case, no, you don't necessarily need them. Robots assume a page should be crawled unless told otherwise. I'd still do it for pages that you don't want indexed and/or followed because a lot of times, robots, especially Google, seem to ignore these directives.
{kind=link}
Got a burning SEO question?
Subscribe to Moz Pro to gain full access to Q&A, answer questions, and ask your own.
Browse Questions
Explore more categories
-
Moz Tools
Chat with the community about the Moz tools.
-
SEO Tactics
Discuss the SEO process with fellow marketers
-
Community
Discuss industry events, jobs, and news!
-
Digital Marketing
Chat about tactics outside of SEO
-
Research & Trends
Dive into research and trends in the search industry.
-
Support
Connect on product support and feature requests.
Related Questions
-

Does Google still use Meta descriptions?
I've noticed that Google is not using my Meta description in the SERP results but rather text from my page, it seems to be a similar situation with a couple of the other sites in the same search results. Does anyone know why this would be?
Technical SEO | | OUTsurance0 -

Multiple robots.txt files on server
Hi! I have previously hired a developer to put up my site and noticed afterwards that he did not know much about SEO. This lead me to starting to learn myself and applying some changes step by step. One of the things I am currently doing is inserting sitemap reference in robots.txt file (which was not there before). But just now when I wanted to upload the file via FTP to my server I found multiple ones - in different sizes - and I dont know what to do with them? Can I remove them? I have downloaded and opened them and they seem to be 2 textfiles and 2 dupplicates. Names: robots.txt (original dupplicate)
Technical SEO | | mjukhud
robots.txt-Original (original)
robots.txt-NEW (other content)
robots.txt-Working (other content dupplicate) Would really appreciate help and expertise suggestions. Thanks!0 -

Robots.txt crawling URL's we dont want it to
Hello We run a number of websites and underneath them we have testing websites (sub-domains), on those sites we have robots.txt disallowing everything. When I logged into MOZ this morning I could see the MOZ spider had crawled our test sites even though we have said not to. Does anyone have an ideas how we can stop this happening?
Technical SEO | | ShearingsGroup0 -

'External nofollow' in a robots meta tag? (advertorial links)
I believe this has never worked? It'd be an easy way of preventing any penalties from Google's recent crackdown on paid links via advertorials. When it's not possible to nofollow each external link individually, what are people doing? Nofollowing and/or noindexing the whole page?
Technical SEO | | Alex-Harford0 -

Meta Title Tags
Hi, Are Meta Title Tag deemed by google to be unique if I use the same phrases by in a different order. For example 3 different pages <colgroup><col width="475"></colgroup>
Technical SEO | | Studio33
| Online Invoicing Software | Online Invoicing | Invoicing Software |
| Online Invoicing | Invoicing Software | Online Invoicing Software |
| Invoicing Software | Online Invoicing Software | Online Invoicing | You will not it is the same keywords just in a different order. Is this unique enough or will google not be happy about it. Thanks Andrew0 -

Need Help with MAGENTO - URL rewrite
Hello... Hopefully a Magento expert will stumble across this question and help me out. I have noticed that my site is no longer as prominent as it once was for specific product pages... I am looking for help in rewriting the URL's for the product pages. I want it to have xyz.com/product (which exists if you hard code it into the site) If you wind up on the product by clicking throught the categories the url looks like: xyz.com/category/subcategory/product. Does anyone know how to make it so when you land on a product page it is just xyz.com/product ? My Site is : http://goo.gl/JgK1e Thanks for the help...
Technical SEO | | Prime850 -

Trying to reduce pages crawled to within 10K limit via robots.txt
Our site has far too many pages for our 10K page PRO account which are not SEO worthy. In fact, only about 2000 pages qualify for SEO value. Limitations of the store software only permit me to use robots.txt to sculpt the rogerbot site crawl. However, I am having trouble getting this to work. Our biggest problem is the 35K individual product pages and the related shopping cart links (at least another 35K); these aren't needed as they duplicate the SEO-worthy content in the product category pages. The signature of a product page is that it is contained within a folder ending in -p. So I made the following addition to robots.txt: User-agent: rogerbot
Technical SEO | | AspenFasteners
Disallow: /-p/ However, the latest crawl results show the 10K limit is still being exceeded. I went to Crawl Diagnostics and clicked on Export Latest Crawl to CSV. To my dismay I saw the report was overflowing with product page links: e.g. www.aspenfasteners.com/3-Star-tm-Bulbing-Type-Blind-Rivets-Anodized-p/rv006-316x039354-coan.htm The value for the column "Search Engine blocked by robots.txt" = FALSE; does this mean blocked for all search engines? Then it's correct. If it means "blocked for rogerbot? Then it shouldn't even be in the report, as the report seems to only contain 10K pages. Any thoughts or hints on trying to attain my goal would REALLY be appreciated, I've been trying for weeks now. Honestly - virtual beers for everyone! Carlo0 -

Google caching meta tags from another site?
We have several sites on the same server. On the weekend we relocated some servers, changing IP address. A client has since noticed something freaky with the meta tags. 1. They search for their companyname, and another site from the same server appears in position 1. It is completely unrelated, has never happened before, and the company name is not used in any incoming text links. Eg search for company1 on Google. Company1.com.au appears at position 2, but at position1 is school1.com.au. The words company1 don't appear anywhere on the site. I've analysed all incoming links with a gazillion tools, and can't find any link text of company1, linking to school1. 2. Even more freaky, searching for company1.com.au at Google. The results at Google in position 1 for the last three days has been: Meta Title for school1 (but hovering/clicking actual goes to URL for company1)
Technical SEO | | ozgeekmum
Meta Description for school1
URL for company1.com.au Clicking on the cached copy of result1, it shows a cached version of school1 taken on March 18. Today is 29 March. Logically we are trying to get Google to spider both sites again quickly. We've asked the clients to update their home pages. Resubmitted xml sitemaps. Checked the HTTP status codes - both are happily returning 200s. Different cookies. I found another instance on a forum: http://webmasters.stackexchange.com/questions/10578/incorrect-meta-information-in-google Any ideas?0