Do I need robots.txt and meta robots?
-
If I can manage to tell crawlers what I do and don't want them to crawl for my whole site via my robots.txt file, do I still need meta robots instructions?
-
Older information, but mostly still relevant:
-
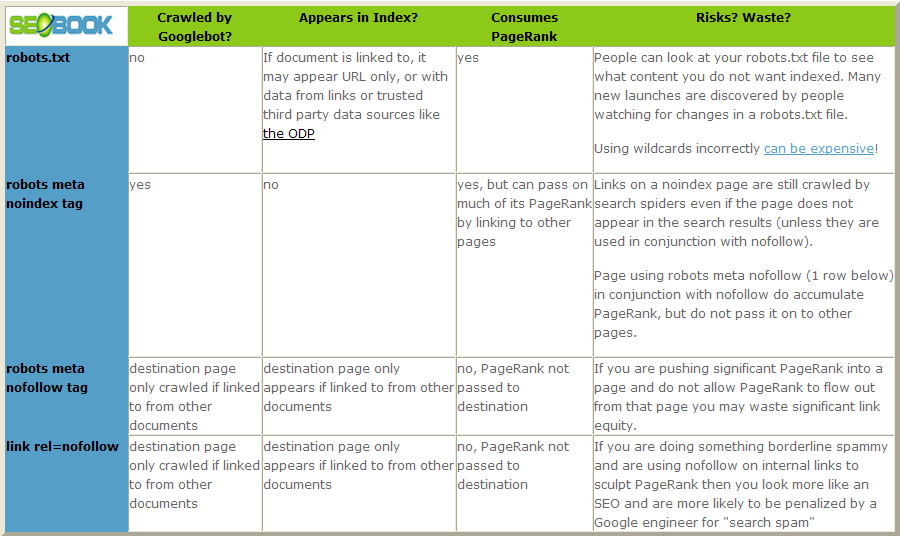
Although robots.txt and meta robots appear to do similar things, they both serve different functions.
Block with Robots.txt - This tells the engines to not crawl the given URL but tells them that they may keep the page in the index and display it in in results.
Block with Meta NoIndex - This tells engines they can visit but they are not allowed to display the URL in results. (this is a suggestion only - Google may still choose to show the URL)
Source: http://www.seomoz.org/learn-seo/robotstxt
The disadvantage of robots.txt is that it blocks Google from crawling the page, meaning no link juice can flow through the page, and if Google discovers the URL through other means (external links) it may show the URL anyway in search results, usually without a meta description.
The advantage of robots.txt is it can improve crawl efficiency - useful if you find Google crawling a bunch of unnecessary pages and eating up your crawl allowance.
Most of the time, I only use robots.txt to solve problems that I can't solve at the page level. I usually prefer to keep pages out of the index using a meta NOINDEX, FOLLOW tag.
-
If you want the stub listing removed as well, this is quite straight forward once you have it blocked in Robots. Instructions here: http://support.google.com/webmasters/bin/answer.py?hl=en&answer=1663419
Just checking though: If the content you are trying to remove is something private that should be hidden (as opposed to just low value stuff that you don't want cluttering the SERPS) then this isn't the right way to go about it. If that is the case reply back.
-
Hello Mat,
As far as I know if I blocked a url using robots.txt.For that page I will get only url in serps but i want to remove url from serps also.How to do that?
-
In short, no. You only need to include the instruction in one or the other. Most people find that the robots.txt file is the preferred solution because it will only take a few lines to specify which parts of a well structured site should and should not be crawled.
-
What do you mean by meta robots instructions? Are you referring to the meta tags that go on each individual page? In that case, no, you don't necessarily need them. Robots assume a page should be crawled unless told otherwise. I'd still do it for pages that you don't want indexed and/or followed because a lot of times, robots, especially Google, seem to ignore these directives.
{kind=link}
Got a burning SEO question?
Subscribe to Moz Pro to gain full access to Q&A, answer questions, and ask your own.
Browse Questions
Explore more categories
-
Moz Tools
Chat with the community about the Moz tools.
-
SEO Tactics
Discuss the SEO process with fellow marketers
-
Community
Discuss industry events, jobs, and news!
-
Digital Marketing
Chat about tactics outside of SEO
-
Research & Trends
Dive into research and trends in the search industry.
-
Support
Connect on product support and feature requests.
Related Questions
-

Need help related to SEO ?
Hi, Hope you guys are doing well! I need help from experts, I have a query that "Does google allows SEO for websites related to crypto currency ?" If yes, what is best way to do SEO for crypto currency website ?
Technical SEO | | JessicaThompson0 -

Robots.txt Disallow: / in Search Console
Two days ago I found out through search console that my website's Robots.txt has changed to User-agent: *
Technical SEO | | RAN_SEO
Disallow: / When I check the robots.txt in the website it looks fine - I see its blocked just in search console( in the robots.txt tester). when I try to do fetch as google to the homepage I see its blocked. Any ideas why would robots.txt block my website? it was fine until the weekend. before that, in the last 3 months I saw I had blocked resources in the website and I brought back pages with fetch as google. Any ideas?0 -

Robot.txt : How to block a specific file type in several subdirectories ?
Hello everyone ! I need help setting up a robot.txt. I'm trying to block all pdf files in particular directories so I'm using this command. In the example below the line is blocking all .gif in the entire site. Block files of a specific file type (for example, .gif) | Disallow: /*.gif$ 2 questions : Can I use this command to specify one particular directory in which I want to block pdf files ? Will this line be recognized by googlebots ? Disallow: /fileadmin/xxxxxxx/xxx/xxxxxxx/*.pdf$ Then I realized that I would have to write as many lines as many directories there are in which I want to block pdf files. Let's say I want to block pdf files in all these 3 directories /fileadmin/directory1 /fileadmin/directory1/sub1 /fileadmin/directory1/sub1/pdf Is there a pattern-matching rule I could use to blocks access to pdf files in all subdirectories instead of writing 3x the above line for each subdirectory ? For exemple : Disallow: /fileadmin/directory1*/ Many thanks in advance for any insight you may have.
Technical SEO | | LabeliumUSA0 -

IIS 7.5 - Duplicate Content and Totally Wrong robot.txt
Well here goes! My very first post to SEOmoz. I have two clients that are hosted by the same hosting company. Both sites have major duplicate content issues and appear to have no internal links. I have checked this both here with our awesome SEOmoz Tools and with the IIS SEO Tool Kit. After much waiting I have heard back from the hosting company and they say that they have "implemented redirects in IIS7.5 to avoid duplicate content" based on the following article: http://blog.whitesites.com/How-to-setup-301-Redirects-in-IIS-7-for-good-SEO__634569104292703828_blog.htm. In my mind this article covers things better: www.seomoz.org/blog/what-every-seo-should-know-about-iis. What do you guys think? Next issue, both clients (as well as other sites hosted by this company) have a robot.txt file that is not their own. It appears that they have taken one client's robot.txt file and used it as a template for other client sites. I could be wrong but I believe this is causing the internal links to not be indexed. There is also a site map, again not for each client, but rather for the client that the original robot.txt file was created for. Again any input on this would be great. I have asked that the files just be deleted but that has not occurred yet. Sorry for the messy post...I'm at the hospital waiting to pick up my bro and could be called to get him any minute. Thanks so much, Tiff
Technical SEO | | TiffenyPapuc0 -

Question about construction of our sitemap URL in robots.txt file
Hi all, This is a Webmaster/SEO question. This is the sitemap URL currently in our robots.txt file: http://www.ccisolutions.com/sitemap.xml As you can see it leads to a page with two URLs on it. Is this a problem? Wouldn't it be better to list both of those XML files as separate line items in the robots.txt file? Thanks! Dana
Technical SEO | | danatanseo0 -

Duplicate Title/Meta Descriptions
Hi I had some error messages in the webmaster account, stating I had duplicate title/meta descriptions. Ive since fixed it, typically how long does it take for a full crawl if Ive fixed these issues? Webmaster is still showing problems with various Title/Descriptions. Also was wondering if I should block individual pages on a large ecomerce site? EX of a Large site - http://www.stubhub.com/chicago-bears-tickets/ (Page is structure and optimized) Then you have all individual games http://www.stubhub.com/chicago-bears-tickets/bears-vs-lions-soldier-field-4077064/ they have an H1 and a meta description, should the page above be blocked from google and concentrate only on the Pain page? Thanks!
Technical SEO | | TP_Marketing0 -

How can I make Google Webmaster Tools see the robots.txt file when I am doing a .htacces redirec?
We are moving a site to a new domain. I have setup an .htaccess file and it is working fine. My problem is that Google Webmaster tools now says it cannot access the robots.txt file on the old site. How can I make it still see the robots.txt file when the .htaccess is doing a full site redirect? .htaccess currently has: Options +FollowSymLinks -MultiViews
Technical SEO | | RalphinAZ
RewriteEngine on
RewriteCond %{HTTP_HOST} ^(www.)?michaelswilderhr.com$ [NC]
RewriteRule ^ http://www.s2esolutions.com/ [R=301,L] Google webmaster tools is reporting: Over the last 24 hours, Googlebot encountered 1 errors while attempting to access your robots.txt. To ensure that we didn't crawl any pages listed in that file, we postponed our crawl. Your site's overall robots.txt error rate is 100.0%.0 -

Should search pages be disallowed in robots.txt?
The SEOmoz crawler picks up "search" pages on a site as having duplicate page titles, which of course they do. Does that mean I should put a "Disallow: /search" tag in my robots.txt? When I put the URL's into Google, they aren't coming up in any SERPS, so I would assume everything's ok. I try to abide by the SEOmoz crawl errors as much as possible, that's why I'm asking. Any thoughts would be helpful. Thanks!
Technical SEO | | MichaelWeisbaum0