Do I need robots.txt and meta robots?
-
If I can manage to tell crawlers what I do and don't want them to crawl for my whole site via my robots.txt file, do I still need meta robots instructions?
-
Older information, but mostly still relevant:
-
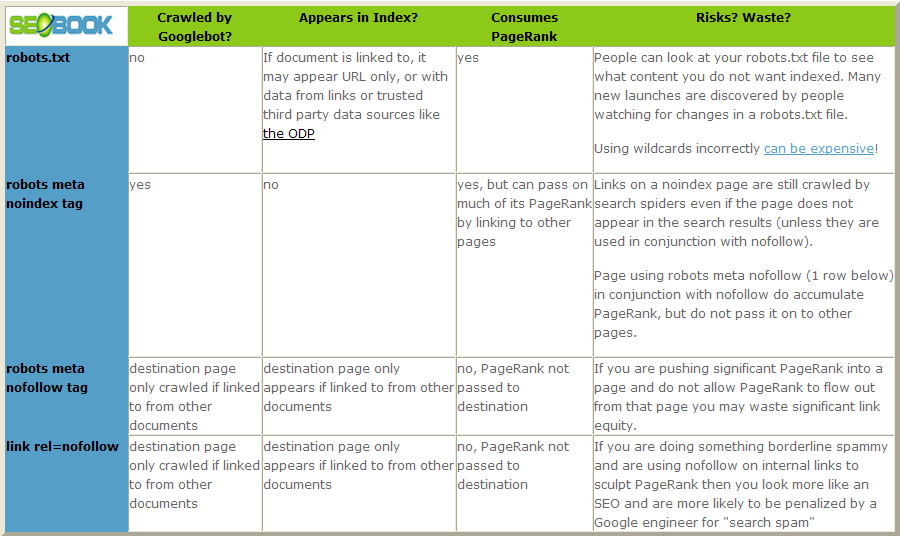
Although robots.txt and meta robots appear to do similar things, they both serve different functions.
Block with Robots.txt - This tells the engines to not crawl the given URL but tells them that they may keep the page in the index and display it in in results.
Block with Meta NoIndex - This tells engines they can visit but they are not allowed to display the URL in results. (this is a suggestion only - Google may still choose to show the URL)
Source: http://www.seomoz.org/learn-seo/robotstxt
The disadvantage of robots.txt is that it blocks Google from crawling the page, meaning no link juice can flow through the page, and if Google discovers the URL through other means (external links) it may show the URL anyway in search results, usually without a meta description.
The advantage of robots.txt is it can improve crawl efficiency - useful if you find Google crawling a bunch of unnecessary pages and eating up your crawl allowance.
Most of the time, I only use robots.txt to solve problems that I can't solve at the page level. I usually prefer to keep pages out of the index using a meta NOINDEX, FOLLOW tag.
-
If you want the stub listing removed as well, this is quite straight forward once you have it blocked in Robots. Instructions here: http://support.google.com/webmasters/bin/answer.py?hl=en&answer=1663419
Just checking though: If the content you are trying to remove is something private that should be hidden (as opposed to just low value stuff that you don't want cluttering the SERPS) then this isn't the right way to go about it. If that is the case reply back.
-
Hello Mat,
As far as I know if I blocked a url using robots.txt.For that page I will get only url in serps but i want to remove url from serps also.How to do that?
-
In short, no. You only need to include the instruction in one or the other. Most people find that the robots.txt file is the preferred solution because it will only take a few lines to specify which parts of a well structured site should and should not be crawled.
-
What do you mean by meta robots instructions? Are you referring to the meta tags that go on each individual page? In that case, no, you don't necessarily need them. Robots assume a page should be crawled unless told otherwise. I'd still do it for pages that you don't want indexed and/or followed because a lot of times, robots, especially Google, seem to ignore these directives.
{kind=link}
Got a burning SEO question?
Subscribe to Moz Pro to gain full access to Q&A, answer questions, and ask your own.
Browse Questions
Explore more categories
-
Moz Tools
Chat with the community about the Moz tools.
-
SEO Tactics
Discuss the SEO process with fellow marketers
-
Community
Discuss industry events, jobs, and news!
-
Digital Marketing
Chat about tactics outside of SEO
-
Research & Trends
Dive into research and trends in the search industry.
-
Support
Connect on product support and feature requests.
Related Questions
-

Will a robots.txt disallow apply to a 301ed URL?
Hi there, I have a robots.txt query which I haven't tried before and as we're nearing a big time for sales, I'm hesitant to just roll out to live! Say for example, in my robots.txt I disallow the URL 'example1.html'. In reality, 'example1.html' 301s/302s to 'example2.html'. Would the robots.txt directive also apply to 'example2.html' (disallow) or as it's a separate URL, would the directive be ignored as it's not valid? I have a feeling that as it's a separate URL, the robots disallow directive won't apply. However, just thought I'd sense-check with the community.
Technical SEO | | ecommercebc0 -

My SERP meta description is displaying 315 characters...
Hi Mozzers, We have recently taken the #2 spot for our main keyword in Google UK serp. I just checked again and we have dropped to #4 and our meta description is no longer there as it has been replaced with some homepage content... 315 characters of homepage content right up to the full stop. I'm a little confused. A couple of our competitors meta descriptions are showing the same, extra long homepage text instead. Is there something totally normal and harmless causing this or do I need to be monitoring/changing something? Has Google made an update to allow for longer meta decs? Any advice appreciated! sWrBcuB.png
Technical SEO | | SanjidaKazi0 -

Robots.txt
Hello, My client has a robots.txt file which says this: User-agent: * Crawl-delay: 2 I put it through a robots checker which said that it must have a **disallow command**. So should it say this: User-agent: * Disallow: crawl-delay: 2 What effect (if any) would not having a disallow command make? Thanks
Technical SEO | | AL123al0 -

Staging & Development areas should be not indexable (i.e. no followed/no index in meta robots etc)
Hi I take it if theres a staging or development area on a subdomain for a site, who's content is hence usually duplicate then this should not be indexable i.e. (no-indexed & nofollowed in metarobots) ? In order to prevent dupe content probs as well as non project related people seeing work in progress or finding accidentally in search engine listings ? Also if theres no such info in meta robots is there any other way it may have been made non-indexable, or at least dupe content prob removed by canonicalising the page to the equivalent page on the live site ? In the case in question i am finding it listed in serps when i search for the staging/dev area url, so i presume this needs urgent attention ? Cheers Dan
Technical SEO | | Dan-Lawrence0 -

Blocked by meta-robots but there is no robots file
OK, I'm a little frustred here. I've waited a week for the next weekly index to take place after changing the privacy setting in a wordpress website so Google can index, but I still got the same problem. Blocked by meta-robots, no index, no follow. But I do not see a robot file anywhere and the privacy setting in this Wordpress site is set to allow search engines to index this site. Website is www.marketalert.ca What am I missing here? Why can't I index the rest of the website and is there a faster way to test this rather than wait another week just to find out it didn't work again?
Technical SEO | | Twinbytes0 -

How long does it take for traffic to bounce back from and accidental robots.txt disallow of root?
We accidentally uploaded a robots.txt disallow root for all agents last Tuesday and did not catch the error until yesterday.. so 6 days total of exposure. Organic traffic is down 20%. Google has since indexed the correct version of the robots.txt file. However, we're still seeing awful titles/descriptions in the SERPs and traffic is not coming back. GWT shows that not many pages were actually removed from the index but we're still seeing drastic rankings decreases. Anyone been through this? Any sort of timeline for a recovery? Much appreciated!
Technical SEO | | bheard0 -

Robots exclusion
Hi All, I have an issue whereby print versions of my articles are being flagged up as "duplicate" content / page titles. In order to get around this, I feel that the easiest way is to just add them to my robots.txt document with a disallow. Here is my URL make up: Normal article: www.mysite.com/displayarticle=12345 Print version of my article www.mysite.com/displayarticle=12345&printversion=yes I know that having dynamic parameters in my URL is not best practise to say the least, but I'm stuck with this for the time being... My question is, how do I add just the print versions of articles to my robots file without disallowing articles too? Can I just add the parameter to the document like so? Disallow: &printversion=yes I also know that I can do add a meta noindex, nofollow tag into the head of my print versions, but I feel a robots.txt disallow will be somewhat easier... Many thanks in advance. Matt
Technical SEO | | Horizon0 -

Severe rank drop due to overwritten robots.txt
Hi, Last week we made a change to drupal core for an update to our website. We accidentally overwrote our good robots.txt that blocked hundreds of pages with the default drupal robots.txt. Several hours after that happened (and we didn't catch the mistake) our rankings dropped from mostly first, second place in Google organic to bottom and mid first page. Basically I believe we flooded the index with very low quality pages at once and threw a red flag and we got de-ranked. We have since fixed the robots.txt and have been re-crawled but have not seen a return in rank. Would this be a safe assumption of what happened? I haven't seen any other sites getting hit in the retail vertical yet in regards to any Panda 2.3 type of update. Will we see a return in our results anytime soon? Thanks, Justin
Technical SEO | | BrettKrasnove0