Do I need robots.txt and meta robots?
-
If I can manage to tell crawlers what I do and don't want them to crawl for my whole site via my robots.txt file, do I still need meta robots instructions?
-
Older information, but mostly still relevant:
-
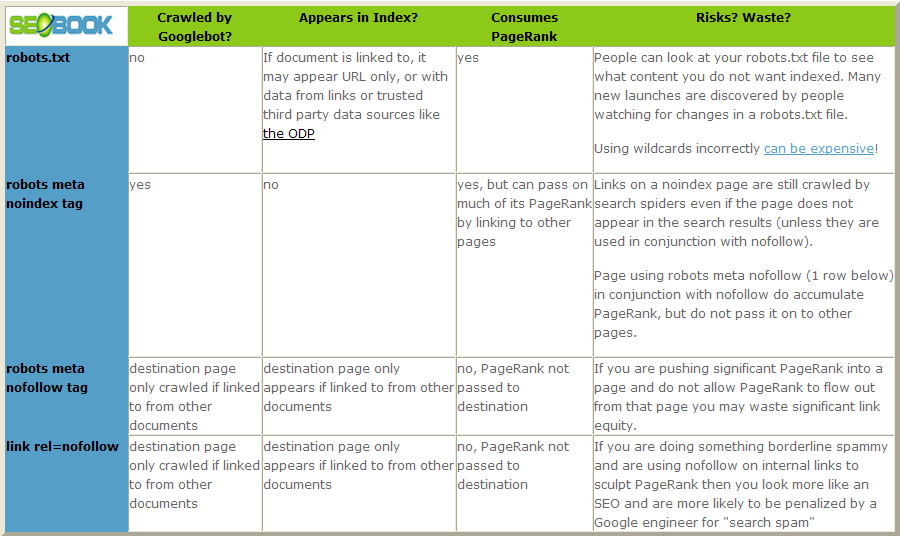
Although robots.txt and meta robots appear to do similar things, they both serve different functions.
Block with Robots.txt - This tells the engines to not crawl the given URL but tells them that they may keep the page in the index and display it in in results.
Block with Meta NoIndex - This tells engines they can visit but they are not allowed to display the URL in results. (this is a suggestion only - Google may still choose to show the URL)
Source: http://www.seomoz.org/learn-seo/robotstxt
The disadvantage of robots.txt is that it blocks Google from crawling the page, meaning no link juice can flow through the page, and if Google discovers the URL through other means (external links) it may show the URL anyway in search results, usually without a meta description.
The advantage of robots.txt is it can improve crawl efficiency - useful if you find Google crawling a bunch of unnecessary pages and eating up your crawl allowance.
Most of the time, I only use robots.txt to solve problems that I can't solve at the page level. I usually prefer to keep pages out of the index using a meta NOINDEX, FOLLOW tag.
-
If you want the stub listing removed as well, this is quite straight forward once you have it blocked in Robots. Instructions here: http://support.google.com/webmasters/bin/answer.py?hl=en&answer=1663419
Just checking though: If the content you are trying to remove is something private that should be hidden (as opposed to just low value stuff that you don't want cluttering the SERPS) then this isn't the right way to go about it. If that is the case reply back.
-
Hello Mat,
As far as I know if I blocked a url using robots.txt.For that page I will get only url in serps but i want to remove url from serps also.How to do that?
-
In short, no. You only need to include the instruction in one or the other. Most people find that the robots.txt file is the preferred solution because it will only take a few lines to specify which parts of a well structured site should and should not be crawled.
-
What do you mean by meta robots instructions? Are you referring to the meta tags that go on each individual page? In that case, no, you don't necessarily need them. Robots assume a page should be crawled unless told otherwise. I'd still do it for pages that you don't want indexed and/or followed because a lot of times, robots, especially Google, seem to ignore these directives.
{kind=link}
Got a burning SEO question?
Subscribe to Moz Pro to gain full access to Q&A, answer questions, and ask your own.
Browse Questions
Explore more categories
-
Moz Tools
Chat with the community about the Moz tools.
-
SEO Tactics
Discuss the SEO process with fellow marketers
-
Community
Discuss industry events, jobs, and news!
-
Digital Marketing
Chat about tactics outside of SEO
-
Research & Trends
Dive into research and trends in the search industry.
-
Support
Connect on product support and feature requests.
Related Questions
-

Why is robots.txt blocking URL's in sitemap?
Hi Folks, Any ideas why Google Webmaster Tools is indicating that my robots.txt is blocking URL's linked in my sitemap.xml, when in fact it isn't? I have checked the current robots.txt declarations and they are fine and I've also tested it in the 'robots.txt Tester' tool, which indicates for the URL's it's suggesting are blocked in the sitemap, in fact work fine. Is this a temporary issue that will be resolved over a few days or should I be concerned. I have recently removed the declaration from the robots.txt that would have been blocking them and then uploaded a new updated sitemap.xml. I'm assuming this issue is due to some sort of crossover. Thanks Gaz
Technical SEO | | PurpleGriffon0 -

Robots.txt
Hello, My client has a robots.txt file which says this: User-agent: * Crawl-delay: 2 I put it through a robots checker which said that it must have a **disallow command**. So should it say this: User-agent: * Disallow: crawl-delay: 2 What effect (if any) would not having a disallow command make? Thanks
Technical SEO | | AL123al0 -

Phone Number In Meta Description
People are more likely to call us, than email us. However, if they're using a mobile device, there's a click to call button on that site. My question is this: google does not include our phone number in our meta description. I could try to get the description changed, but it doesn't seem like it would make that big of a deal for just the desktop site. Am I missing something about the importance of the phone number on a desktop site? Any experience with this situation? Thanks, Ruben
Technical SEO | | KempRugeLawGroup3 -

Two META Robots tags on a page - which will win?
Hi, Does anybody know which meta-robots tag will "win" if there is more than one on a page? The situation:
Technical SEO | | jmueller
our CMS is not very flexible and so we have segments of META-Tags on the page that originate from templates.
Now any author can add any meta-tag from within his article-editor.
The logic delivering the pages does not care if there might be more than one meta-robots tag present (one from template, one from within the article). Now we could end up with something like this: Which one will be regarded by google & co?
First?
Last?
None? Thanks a lot,
Jan0 -
Is the " meta content tag" important?
I am currently trying to optimize my companies website and I noticed that meta content is exactly the same for all of the pages on our website. Isn't this problematic? The actual content on the webpage is not the same and a lot of the pages don't have these keywords in the content.
Technical SEO | | AubbiefromAubenRealty0 -

Very, very confusing behaviour with 301s. Help needed!
Hi SEOMoz gang! Been a long timer reader and hangerouter here but now i need to pick your brains. I've been working on two websites in the last few days which are showing very strange behaviour with 301 redirects. Site A This site is an ecommerce stie stocking over 900 products and 000's of motor parts. The old site was turned off in Feb 2011 when we built them a new one. The old site had terrible problems with canonical URLs where every search could/would generate a unique ID e.g. domain.com/results.aspx?product=1234. When you have 000's of products and Google can find them it is a big problem. Or was. We launche the new site and 301'd all of the old results pages over to the new product pages and deleted the old results.aspx. The results.aspx page didn't index or get shown for months. Then about two months again we found some certain conditions which would mean we wouldn't get the right 301 working so had to put the results.aspx page back in place. If it found the product, it 301'd, if it didn't it redirected to the sitemap.aspx page. We found recently that some bizarre scenerio actually caused the results.aspx page to 200 rather than 301 or 404. Problem. We found this last week after our 404 count in GWMT went up to nearly 90k. This was still odd as the results.aspx format was of the OLD site rather than the new. The old URLs should have been forgetten about after several months but started appearing again! When we saw the 404 count get so high last week, we decided to take severe action and 301 everything which hit the results.aspx page to the home page. No problem we thought. When we got into the office on Monday, most of our product pages had been dropped from the top 20 placing they had (there were nearly 400 rankings lost) and on some phrases the old results.aspx pages started to show up in there place!! Can anyone think why old pages, some of which have been 301'd over to new pages for nearly 6 months would start to rank? Even when the page didn't exist for several months? Surely if they are 301's then after a while they should start to get lost in the index? Site B This site moved domain a few weeks ago. Traffic has been lost on some phrases but this was mainly due to old blog articles not being carried forward (what i'll call noisy traffic which was picked up by accident and had bad on page stats). No major loss in traffic on this one but again bizarre errors in GWMT. This time pages which haven't been in existence for several YEARS are showing up as 404s in GWMT. The only place they are still noted anywhere is in the redirect table on our old site. The new site went live and all of the pages which were in Googles index and in OpenSiteExplorer were handled in a new 301 table. The old 301s we thought we didn't need to worry about as they had been going from old page to new page for several years and we assumed the old page had delisted. We couldn't see it anywhere in any index. So... my question here is why would some old pages which have been 301'ing for years now show up as 404s on my new domain? I've been doing SEO on and off for seven years so think i know most things about how google works but this is baffling. It seems that two different sites have failed to prevent old pages from cropping up which were 301d for either months or years. Does anyone has any thoughts as to why this might the case. Thanks in advance. Andy Adido
Technical SEO | | Adido-1053990 -

Use of Meta Tag - MSSmartTagsPreventParsing
We've inherited some sites from another developer that had the following tag: All references I can find to it are from 2004. What is the purpose and is it worth including in pages/sites we build?
Technical SEO | | wcksmith0 -

Meta Description On Categories
Is it really necessary to add a meta description to your categories and admin pages? I don't even have that option with my Genesis platform. When i received my first crawl test, those are the things that stick out as errors...
Technical SEO | | brentmitchell0